

朱小强|屠龙少年与龙:漫谈深度学习驱动的广告推荐技术发展周期
原文2021.08 发表于知乎 漫谈深度学习驱动的广告推荐技术发展周期
写在前面
2019年初,在深度学习浪潮涌起之际,以当时我所领导的阿里展示广告模型团队的技术发展轨迹为参考,我写了一篇技术总结:镶嵌在互联网技术上的明珠:漫谈深度学习时代点击率预估技术进展(下文多次引用,简称“ 互联网技术明珠 ”) 。 时隔2年半,再回头看那篇帖子,当时看到的、想到的、预测的,对照着随后真实发生的、成功或失败的、过程中我们思考与推动的,有一种万流汇海、豁然开朗的感觉。回顾这个过程也再次让我清晰地看到了整个领域奔腾汹涌但又层次分明的不同发展阶段。这种体验有着极强的画面感,饱含着“大江大河”般的时代演变色彩,让我有种不吐不快的冲动。加之,我即将开启自己下一阶段的职业生涯,奔赴全新的战场。曾经的这些思考若就此散落在风中,也有点可惜。因此动笔写了这篇总结。
我们的不少工作都通过论文或者技术分享单点对外讲过,不过我跟业界的交流来看,知识过于碎片化,缺乏系统的脉络整理;大都同学关注的是单个算法怎么拿效果,而忽视了更大的系统性机会和空间。因此,本文的出发点是希望掀开纷繁复杂的业务外壳、抛却炼丹调参的奇技淫巧,回归到技术演化的主轴本身,以我们的实践经验为引,从宏观尺度来看一看技术演化的脉络,更多分享我们在技术迭代背后的思路和思考,我想这是远远比解读一篇论文或者技术的细节更有意义。当然,假大空地谈方法论、讲各种华而不实的思考是没有营养的,因此本文照例还是以我曾经战斗过的阿里广告技术实践为蓝本,力图给大家更详实的体感(当然只限于团队已经公开的部分技术及相应地我个人的思考,基本的职业操守必须遵守)。
得益于近些年我有机会领导了整个阿里展示广告技术团队(原名精准定向广告团队),使得我有更好的站位来审视技术体系整体,因此本文中我会系统地谈一谈我对包括召回、粗排、精排,甚至工业级AI基建体系、引擎架构等的思考。这些技术本身,从大的尺度来看一定会随着不断的迭代和更新散落在时间的长河里面,逐步被淘汰、直至被历史淹没。但是,在这样一个特定的技术发展阶段中,从小心翼翼的探路到看清方向后的大规模All-in;从享受技术代际变革带来的红利到第一波红利期过后继续创造出第二增长曲线的续力;从新锐的技术革新者到“飞入寻常百姓家”变成新的技术基石——见证与主导这样一个完整的技术演化周期所带来的经验沉淀和认知升级,有着无与伦比的价值和对未来的泛化性。这是我希望传达和分享的核心内容。本文适合两类读者:
- 入门不久或者还在学习中的行业新人。按图索骥,可以参考主要技术模块的发展过程和具体技术解法。
- 大/中型搜推广技术团队的负责人。以史为鉴,可以参考技术体系设计背后的思考和设计哲学。
提醒: 本文非常的冗长,26000多字,建议收藏后找个完整的时间阅读。所有的引用都直接以超链接形式存在,点击即可跳转。
一、深渊与恶龙:浅层机器学习时代末期的技术困境
如果是近几年新加入到这个领域的从业者们,应该对深度学习爆发之前、浅层机器学习主导的工业界技术史缺乏足够的了解。而这段历史,又对今天的工业级深度学习在遭遇到新瓶颈后的做法有着惊人的参考性,因此我们先耐心地花点时间写段简史。
跟如今流派纷繁多样、技术创新不断的局面截然不同,那个时期LR、GBDT、SVM、CF等可数的几个模型几乎统治了整个工业界。能够讲明白GBDT的原理、能手推SVM优化、懂得VC维理论、会MPI并行开发的已经是一流的选手;如果有幸在大型互联网公司工作过、懂得大规模分布式LR模型的调优和并行训练、对大规模特征工程有经验的同学,哪怕是实习生,更是各大公司争抢的顶端人才。
站在今天来看,那是一片贫瘠的技术荒原,时间大致覆盖了2005到2015这10年 。尤其是2010年之后的5年,G家和B家是绝对的技术统治者。以计算广告领域为例,我个人的观察中,当时国内绝大部分公司的广告团队都采用的是G/B的方案:大规模分布式LR模型 + 庞大的人工特征工程队伍。G家放出一个FTRL的论文,整个国内工业界趋之若鹜,甚至连paper中笔误的地方都有专题讨论。当然,工业界相关的论文更是凤毛麟角,大家都敝帚自珍、视为公司的核心机密。当时技术的主流路线是:不停改进LR模型的分布式优化算法以提高训练速度 + 不停地爆特征、人工交叉组合以提高模型精度。算法工程师很大一部分工作就是围绕着特征工程构建工具、试验特征离散化方案、调整参数、评估模型,以至于有人喊出“工业界不需要懂机器学习的人、只要懂特征工程的人就行”的口号,对学术界那些复杂的、几乎难以在工业界跑得动的模型往往是不屑一顾,学术界和工业界也基本是各玩各的、老死不相往来。大约2011年暑假我有幸跑到凤巢实习了几个月,见证和参与了恐怖的万亿量级特征工程项目。能否快速训练超大规模分布式模型,成了那个时期技术竞争力的最重要指标。
然而,用工程的解法来提升算法的精度,明显是有天花板的。因此也有人把目光转向了非线性。这里出现了两个流派,一派是通过前置的非线性模型给LR自动地进行特征工程,例如GBDT+LR方案(来自fb)、PLSA+LR方案等等;另外一派走得更彻底、某种程度上算是后来深度学习时代的先驱者,采样的方案是直接端到端训练大规模非线性模型,例如FM模型以及我们团队的MLR模型。我在“互联网技术明珠”一文第二章第0、1两小节有详细的介绍,这里不赘述。然而哪怕是端到端非线性模型流派使用的本质上还是浅层的模型,受限于模型非线性刻画能力的限制,在这条路上走得很艰难。以我们为例,在2014-2015年也不得不在MLR模型的基础上叠加第一个流派的做法,开始尝试人工特征组合+MLR、PLSA+MLR等。要注意的是,在当时要实现一个能够支撑真正的工业级生产能力的分布式模型训练程序,只有非常顶尖的团队有实力做到。因此,这种“ 大量前置的级联模型 + 继续拼分布式训练的规模化能力 ”方案导致整个技术的迭代效率非常低:一个idea动辄要数月甚至更长时间才能完成公式推导、代码编写、模型训练和线上AB实验,耗费的机器更是需要数百台独占的MPI服务器。

图1:浅层机器学习时代(2005-2015)的主流广告技术
这些本质上因为底层技术遭遇瓶颈、如同掉入黑暗的深渊而不得不跟技术的恶龙殊死搏斗、靠四处挖坑续命的问题,我曾把它们戏称为那段时期工业界的几朵乌云。历史总是有着惊人的相似性,下文我们看到深度学习驱动的技术体系变革在走到新的瓶颈期后,何尝不是如此呢。
二、屠龙宝刀:工业级深度学习1.0的红利期
黑暗褪去、曙光乍现的契机来自学术界,一本叫做深度学习的武林秘籍横空出世、大杀四方,成为了新的技术王者。
我在大约2006年左右第一次接触人工神经网络模型,2009年夏天第一次接触深度学习,2013年在第一家公司专题分享过深度学习。然而当2015年我在MLR遭遇瓶颈、重新把视野转向深度学习的时候,发现整个知识体系发现了巨大的变化,跟几年前我熟悉的DBM预训练模式截然不同,训练方案简洁多了,深度学习的热度也明显出现了持续的上涨趋势,尤其是NG在G家搞出来的端到端猫分类模型,打开了无穷的想象力。于是,从2015年底我们开始认真探索深度学习在工业界的应用可能性。在2016年夏天第一次探测到深度学习的威力后,我正式在团队里面确立了深度学习战略、决定整个团队ALL-IN深度学习。当时我同时负责阿里妈妈定向广告的rank模型团队和机器学习平台团队。在随后的几年时间内,我们迅速地以深度学习为屠龙宝刀驱动了阿里广告技术的全面变革,进入到一个空前繁荣、技术创新百花齐放的红利期。
这段经历教会了我两个非常重要的认知:体系性迭代思维和 工具思维 。得益于团队原有的基础,我们在看到深度学习巨大的潜力时,迅速地铺开了两条发展主线。
- 第一条主线比较好理解,围绕着算法体系做布局。我在“互联网技术明珠”一文中花了大量篇幅做介绍:从最简单的分组全连接网络GwEN开始,我们沿着横纵双轨道看准并站上了多个关键的技术高地,包括用来提取互联网个性化行为中兴趣多峰分布的attention式网络、刻画兴趣变化的GRU式结构;以多目标、多模态为主的MTL技术、Transfer Learning技术等等。这些技术点站在现在来看没什么特别,但在整个业界还处于蛮荒期时,在阿里这种大规模的生产业务中独立研发并落地应用,有着极强的超前性。
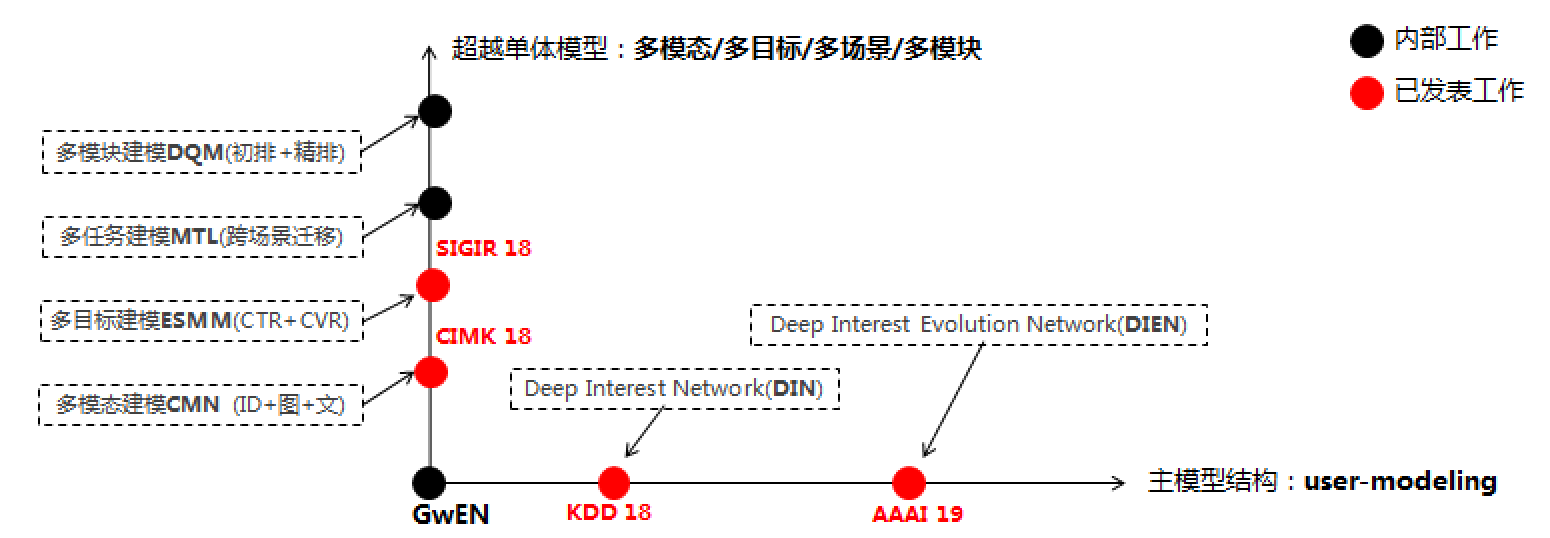
图2:深度CTR模型算法演化双轨道(2016-2018)
- 第二条主线是围绕算法创新打造趁手的兵器。算法水平决定了收益的高度;基建水平决定了获取收益的速度。这一点在“互联网技术明珠”一文中没有展开,但是我在18年主导XDL(X-DeepLearning)开源时,在阿里内部的ATA技术社区中撰文详述了这背后的研发故事。虽然技术干货不多,但技术的判断和曲折过程对心力有很强的锻炼,阿里的同学感兴趣的可以搜一搜看看。可以说16年我们启动深度学习战略时,在那个战略窗口期花大力气打造出来的这个工具,极大地助力了我们在算法上的各种匪夷所思的创新,且确保了惊人的迭代速度。
此外,阿里在这段时期业务的高速发展积蓄出强大的自信,形成了鼓励技术开放、跟业界高手过招的绝佳氛围,我们把一些落地到业务产生巨大收益的创新成果如DIN/DIEN/ESMM等总结成论文发表;同时把最初为自己的快速算法创新打造的趁手兵器——面向高维稀疏数据场景定制的分布式深度框架XDL也开源出来贡献给了业界,收获了不小的关注。
这个阶段我称之为 工业级深度学习1.0。 回看我们团队的发展历程,大致的时间窗是2016-2018这三年。站在整个业界来看,我们属于第一批深度学习的掘金者和领航者,技术的创新也给阿里的广告业务带来了巨大的红利。在这个阶段,整个业界技术的头部玩家也出现了变化,不再是美国独大、G家独大。据我所知,我们团队的不少工作已经大量地被包括中美在内的头部公司、头部团队所研读、借鉴甚至直接应用。不少海外工作的朋友跟我聊起时,对包括我们在内的国内众多顶尖团队的技术厚度赞不绝口,普遍认为超过了美国大部分的企业。
值得提一下是,在工业级深度学习1.0阶段最早感知底层技术升级、随后产生剧烈变革的是精排CTR模型,不论是广告还是推荐都类似。这也很好理解,CTR模型相对来说well define,对业务的效果影响直接且巨大,投入的性价比极高,因此是1.0阶段技术创新的主战场。其它的技术模块包括召回、粗排、广告auction/推荐rerank等,在这个时期还没有进入到大爆发期。随着精排CTR模型带动了整个基建体系和方法论完成了一波升级后,它们才进入了节拍。
我在“互联网技术明珠”文章的最后一段总结过工业级深度学习1.0阶段的关键词:端到端的算法变革。这个阶段有一个影响技术史走向、起着决定性力量的基建技术:深度学习框架。在深度学习框架范式下,普通的算法同学可以搭积木式设计模型,不再需要复杂的手工推导优化算法,不再需要编写复杂繁重的分布式训练程序。尤其是多个优秀框架的纷纷开源,通过python即可实现任意复杂的模型编程,这直接推动了整个领域技术跃上了新台阶。此时,在工业界数据和算力都准备充足的情况下,深度学习算法爆发的惊天一击威力巨大,破坏式创新使得上一代以“大规模分布式LR模型 + 人工特征工程”为盟主的技术体系冰消瓦解,彻底解放了生产力, “模型工程” 真正地走上了历史的舞台,工业界和学术界前所未有地连接在一起,各种充满奇思妙想的算法创意层出不穷,一时百舸争流、热火朝天。
然而,繁荣中也蕴含着隐忧,曾经的推力转眼间就变成了阻力。得益于我们团队在春江水暖的初期就全面拥抱了深度学习技术体系,大致在18年底、在业界还在纷纷追赶深度学习技术变革浪潮的时候,我们很快就看到了危机:深度学习的变革过于猛烈,迅速吞噬掉过去十多年积累下来的数据和算力存量。业界大部分头部的、深度学习变革较为彻底的团队,都已经进入到相对滞涨阶段。我在“深度学习推荐系统电子版序”一文中总结过工业级深度学习1.0达到顶峰的几个标志:
1)搭积木式的模型架构演进,其边际收益越来越低;
2)深度模型进入数据饥饿阶段,希望进一步通过10倍、100倍的数据量来填充既有模型容量(model capacity),从而提升精度;
3) 大部分新的大型算法优化和改进,都需要工程系统架构配套进行巨大的升级改造。
当时有一点还没有看得很清楚,因此在序言中没有很好的总结的是算力这个点。19年开始,我们发现算力的极度吃紧成为了算法创新在工业界落地的新瓶颈。以我们团队为例,过去的4、5年时间,模型算力需求的平均年化增长率是200%-300%,换句话说,5年后的今天单模型使用的算力平均是2017年初DIN模型的100倍左右。这个增速是恐怖的,且随着模型的逐渐复杂,这个增速其实还在进一步提升。
对工业级深度学习1.0逐渐显现出来的瓶颈的观察,催化了我们对新技术体系的思考,从而指引着我们打造了工业级深度学习2.0的第二增长曲线。
三、宝刀未老:工业级深度学习2.0的深水区跋涉
这一章是我在“互联网技术明珠”文章末尾留下的彩蛋,也是我带领团队在2019年之后、沿着深度学习2.0的深水区跋涉后大量实践的系统性总结,因此会做详细的展开,占据本文80%的篇幅,阅读需要些耐心。这个阶段的工作主要涵盖2019-2021的时间窗。
首先介绍下 “技术水位的漫延效应 ”。上一章也提到过,精排模型是深度学习落地工业级应用的第一主战场,随着这种端到端建模方法体系以及AI基建能力的逐步完善,开始如水流一样溢出并漫延到技术全链路的各个低洼区。以广告技术为例,召回、粗排、bidding与auction、以及引擎架构等随之产生了剧烈的重构升级,带来了全链路技术体系的整体变革。具体到阿里展示广告的技术发展路径,比较典型地符合着这个趋势。不过,篇幅有限,下文中我不会沿着时间的轨迹来展开技术在每个时间节点的详细发展过程,而是从大家熟悉的召回、粗排、精排等算法链路和基建能力视角,以模块为主体总结性地介绍我们的实践和思考,但读者要清楚技术的梯队发展路径,这样能更获得更深入的理解。
- 召回技术
召回技术以往单点技术创新介绍的文章不少,但系统性的总结不多,我多写一点 。业界比较常见和通用的做法是构建各种各样的召回通路,规则启发式的、重定向式的、向量召回式的等等,最后做一个通道融合。这导致了几方面的问题:
1)召回通道越积越多,维护的代价极大;
2)单通道覆盖的流量比例往往都不大,据我所知普遍低于30%,从而导致任一通道的技术升级对大盘的影响都被稀释,花80分力气带来20分收益(负向2/8现象);
3)通道之间缺乏协同性,不同通道之间召回结果的overlap较大,召回技术缺乏整体迭代的方法论。
历史原因,阿里展示广告之前的召回技术也存在以上的痛点,导致我们单点的技术厚度非常强(TDM系列技术),但体系性发展空间受限。对此,我给出的解法是:
1)全力推进model-based召回技术研发,投入重兵推进内核的召回算法创新,尽力砍掉小众琐碎的规则式召回通道,让整个召回技术收敛成最多2-3个算法簇,覆盖的流量占比超过80%,形成正向的2/8现象;
2)在模型簇召回技术的基础上建设多召回通道联合建模的算法,通过learning的方法构建通道之间的协同通信,在固定的召回quota下最大化召回集合的多样性;
3)从算力的视角思考召回系统,构建更强大的系统能力,使得召回的quota提升一个数量级以上。
换言之,我希望召回的体系演变成短平快的可迭代体系:既能够大力出奇迹,扩大输送给后链路的召回集合规模;又能够充分发挥深度学习end-2-end learning的优势,通过具备协同能力的、有限的模型簇构建的多召回通道,最大化地优化召回集合的精准度和多样性,且这种model-based主导的召回体系具备较强的可迭代性。
从目前的进展来看,解法1和3的进展比较顺利,很快就能产生强大的生产力,解法2理论框架构建完毕,但真正要发挥作用依赖1和3两条腿都落地。这一节我重点介绍召回的内核算法及协同建模的思路,系统能力部分留到后面整体介绍。
1.1 TDM技术体系回顾
2017年开始,阿里展示广告团队独立提出并研发了基于tree结构、支持复杂深度学习模型进行全库检索召回的TDM技术体系,如下图3所示。TDM技术极富创意,开辟了一个全新learning to retrieve领域,且我们真正落地在阿里展示广告这样一个规模足够大的场景,取得了显著的业务收益,这证明了技术的有效性。关于TDM技术的详细介绍,相信不少同学都已了解,这里我偷下懒,直接引用知乎上几个热心的解读文章。
- TDM 1.0解读:https://www.zhihu.com/question/362190044/answer/970781462
- TDM 2.0解读:https://zhuanlan.zhihu.com/p/93424358
- TDM 3.0解读:知乎上没看到,这里放出一作卓靖炜同学公开分享的文章。

图3:TDM技术体系
然而TDM技术也有其固有的不足:首先是整个系统比较重,不论是训练系统还是在线serving系统,带来的挑战是TDM只能训练得动短短几天的样本(例如,我们典型的TDM模型只用了一天的样本),丧失了对长周期信号的捕捉能力;其次TDM中item/ad是tree的叶子节点,这导致了TDM建模的时候对item侧的很多side information难以利用上,因为这些信息无法向上层节点上溯;最后,TDM的算力消耗跟效果的tradeoff不太好balance,使得模型的复杂度还是显著受限。这些固有的不足,催生了我们进一步发展更加轻量级、可迭代、扩展性强的复杂模型全库召回技术体系。
1.2 算力效能驱动的轻量级全库召回技术
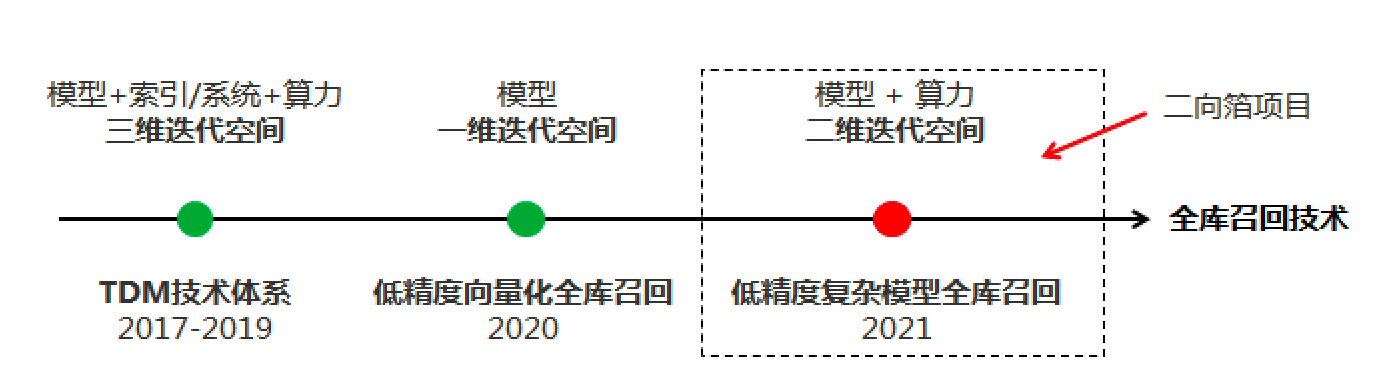
图4:三代全库召回技术
从2020年开始,我们从另外一条路径发起了对这个问题的冲锋,引入算力、算法和架构co-design的视角,形成了新的解法。图4给出了我们的技术发展过程。在TDM之外,我们首先试水了基础的向量召回技术。跟常规意义上沿着更好的向量建模视角出发不同,我们首先试着把算力效能技术(下文第5小节会详细介绍)引入进来,摸底了“暴力扫全库”技术的可行性。传统的向量召回其实不是真正意义上的全库计算,真正在线召回的时候是通过PQ等近似近邻技术对全库向量集合做了约减,从而只对部分集合进行了计算,这导致向量召回技术的training-inference mismatch问题。为此,我们引入了低精度算力技术,在阿里广告业务规模下第一次真正意义上实现了向量化全库召回,相关的论文不久就会公开出来,敬请期待。
然而,众所周知,向量式的双塔结构本身已经bound住了模型的表达能力。业界也发展出了一系列基于GNN的技术,可以有效引入各种丰富的异构side information,极大地提升了user和item/ad embedding的信息量,但是这种结构范式下对应的天花板是明显存在的。
在成功研发出了低精度向量化全库召回技术后,我们进一步沿着算力的视角出发,发展出了最新的低精度复杂模型全库召回技术。这个项目的 内部代号是二向箔 ,寓意来自于 《三体》的维度战争武器 :在构思二向箔技术时,我形象地把TDM技术看成模型、索引/系统、算力三个自由度都打开的全库召回技术,它的天花板足够高,但略重,导致进一步迭代的技术债有点高;而向量化全库召回技术则相反,它通过向量化的范式,把系统和算力的消耗控制在了极低的水平,技术体系非常的轻便,可以容纳和叠加很多新的技术,如GNN等,但天花板有限;二向箔技术居于中间,目标是将系统这个维度积分掉,建立“模型精度和算力消耗”这两个自由度(维度)的可控平衡;它沿用暴力扫全库的系统实现思路,实现一个既灵活可迭代、同时又能够在给定的算力约束下支持任意复杂的信号(突破TDM在item侧缺信号的弱点)、任意复杂的模型(突破向量式双塔模型表达能力弱的限制)的全库召回技术。
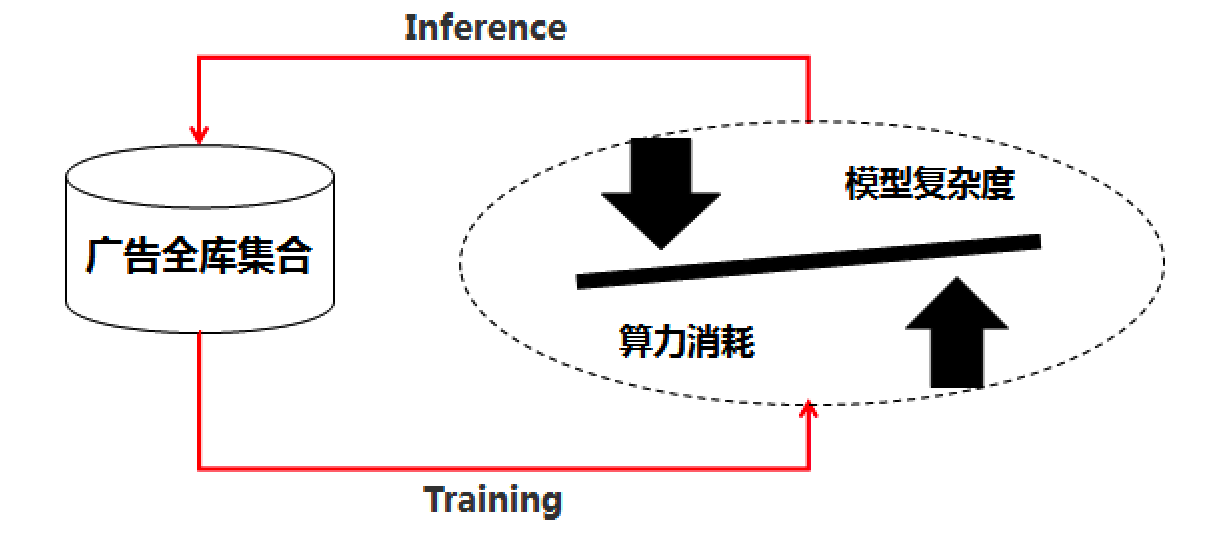
图5:二向箔技术的思路简图
对我们团队工作熟悉的同学,应该知道去年发布出来的全实时在线粗排系统COLD架构(下一节也会详细介绍)也是采用了二向箔类似的思路:构建模型复杂度和算力可以tradeoff的架构,从而打开了全新的粗排技术空间。只不过二向箔是面向召回的模型化架构,跟粗排有着显著不同,这些不同也是复杂模型全库召回技术要攻坚的核心,包括:
- **[更低精度] **粗排本质还是一个给定相对准确的候选集进行topk筛选的过程,因此粗排模型的score需要足够的数值精度;而召回模型的任务是从全库“生成”规模足够大的集合,它的数值精度相比粗排而言可以低很多,这从原理上提供了对召回模型实施足够的低精度量化的空间,也相应地给了召回模型更大的自由度进行算力和算法复杂度的tradeoff,例如int8相比于常规的float精度,背后的算力消耗有着可观的差异;
- **[更粗分辨率] **粗排是后继精排的前哨站,因此它的求解空间还是可以定义在ranking的范畴内,相应的粗排模型样本的构造,大都还是以精排及往后阶段的正负样本比较为目标(不一定是点-展样本,现在比较多的团队采用精排队列来构建正负样本);而召回则不然,尤其是全库召回模型的分辨率要求具备极粗粒度筛选的能力,它要分辨的尺度比粗排要粗1-2个数量级,因此相应的正负样本构造就是要仔细设计和攻坚的。这其实还是个open问题:对任意一个用户,能否以及如何从有限的已知信号(如点-展样本、各种点击/购买等行为)构建模型,从千万量级全库集合中召回有效集合。这里面的popularity bias问题、模型泛化问题等都还没有好的解法。
目前二向箔项目已经在我们的业务中取得了第一期显著的收益,在可期的时间内二向箔技术体系会通过论文、开源等形式跟大家见面,我就不泄密了、给团队留白。
当然,要强调一下,包括TDM、二向箔在内的全库召回技术都是在线实时计算的技术体系。如果用户兴趣变化的时效性不强,还有另外一条可行路径,采用近线计算的方式摆脱实时计算对latency和算力的约束,空间换时间,采用任意复杂的模型、以低频率更新的节奏(如每天/周执行一次)提前计算好每一个用户在全库空间中的召回结果,将其存储在分布式内存(如memcache)中,在线用户访问的时候直接读取缓存的召回结果就行。另外,这里的计算消耗又可以利用低频率更新模式下算力可以削峰填谷的优势,从而在总算力基本不增的情况下完成任意复杂度的全库召回近线计算任务。当然,对于广告场景而言,远不止这么简单,因为广告的价格、以及广告主圈选的定向条件限制等可以随时发生变化,因此还需要一个通路来执行delta更新,这样对这套近线计算系统的要求就比较高。我们团队在这条路径上也走得较远,用来作为在线复杂计算的补充,感兴趣的同学可以阅读我们的TFMS论文(3rd DLP-KDD workshop 的 best paper )。当然,这个工作主要不是设计来解决全库召回的近线计算问题,只是提供了一种可行的架构解,读者看的时候不要困惑。
回到在线实时计算的全库召回技术,站在当下我对这三种全库召回技术的预判:二向箔技术可能演变成终局,取代掉TDM和低精度向量全库召回两个技术,因为从原理上来看,二向箔的模型同时兼容TDM和向量式双塔结构。当然更现实的路径可能是未来一段时间,TDM技术和二向箔技术会短暂地并存,因为TDM技术发展出来的面向多种业务目标优化的能力相比于初期的二向箔还是有优势的。
1.3 多定向协同建模
最后简单讲一讲如何解决多个召回通道融合的问题。前面阐述过我的观测:业界绝大部分团队都是采用堆砌召回通道、append的模式,导致通道间召回集合重叠严重、浪费有限的quota。我们的思路是在主流量被model-based召回算法覆盖后,采用联合建模的方式,强化通道之间的通信与协同。

图6:多通道召回联合建模示意图
这里面的要点包括:
1)loss函数包括两部分,一部分是任意单一模型在label域的loss(简称label loss);第二部分是对模型召回集合的loss(简称set loss)。只不过实操中大部分的召回模型都还是point-wise的形式,因此set loss需要能被分解到任意一个候选item/ad上进行计算(label loss天然满足这一点);
2)set loss的设计是多通道协同的关键,比如一种straight forward的、我们实践过的方案是定义set的diversity(多样性),进一步我们把这个diversity近似为embedding向量之间的距离,这样可以直接带来给定召回集合quota下diversity的提升,背后实际相当于让不同模型的召回集合强行推向了互补的空间。
不过,如前文提及我们目前的重心是在构建更强的全库召回技术以及支持更大规模召回集合的系统能力,且现有业务中召回算法的数量还没有完全收敛,因此多定向联合建模当前的进展偏慢,理论框架和初期的实践跑通了,但真正发挥威力还需要前置条件到位。期待在将来的某个时间,我能听到团队小伙伴们将这个技术深度推进、取得实质性成果的消息。这是我觉得可以给召回技术带来底层突破的增量机会,当然难度也较大。
2. 粗排技术
相比于召回和精排技术而言,粗排是一个冷清的角落,花大精力研究和思考的团队似乎不多,相应地粗排技术的进展也缓慢一些。
去年在COLD论文中我总结过:业界对粗排技术主流的观点是认为粗排是精排模型的一个低算力简化版本,因此精力都用来进行精排模型的简化,以满足粗排在更大候选集、更严格的latency约束下的系统性能要求。因此双塔式粗排模型就成为了大家一个自然的选择,算力和latency消耗都极简,这也是我们在COLD之前的粗排版本。
对粗排技术,其实我们团队有过远比COLD论文呈现多得多的算法探索。而大部分探索,都需要一个足够高效、可迭代的系统架构支撑,最好像精排的技术体系一样灵活。因此实际上,COLD的这个系统是我在推动粗排技术升级的最初、大约是2019年的时候就构思并全量落地的产物。只不过,真正在粗排算法上的突破姗姗来迟,直到2020年下半年才有了较多的进展。因此在2020年的时候我们把COLD作为算法、算力和系统架构co-design的一个典型case总结出来,发表在2nd DLP-KDD上,很荣幸获得了最多的投票被选为当年的best paper。关于COLD以及COLD之前粗排技术的优劣势、特点等等,COLD论文中已经写得很详细,我就不赘述。一作的作者王哲同学在2020年datafun年会上也对COLD做过精彩的分享,里面有对粗排技术的进一步思辨,值得一看。此外,粗排模型算法上一些最新的进展相信后续团队也会系统地进行总结,通过paper或者分享的形式对外呈现,我先留白。这里我更多的想跳出粗排技术本身,引申来探讨两个重要的话题:
- 话题1:算法、算力与系统架构的关系
2018年左右,我开始在业界提出 工业级深度学习2.0的理念 ,当时的判断:“算力驱动,算法引发的第一代工业级深度学习技术变革,本质是在上一代系统架构体系约束下,释放了单点算法红利;新挑战/机遇的解法是算法+算力+系统架构的co-design:集结单点算力和算法优势,重新定义新的系统架构体系”。相对而言,算法所需要的算力、系统架构两项,以往更多的是拆解和交由纯引擎工程团队负责。然而引擎同学缺乏对进展如此之快的算法的充分了解,完全由他们来研发与新算法生产力适配的算力和系统架构速度偏慢、且方向未必准确。为此,我 组建了业界第一支(据我所知)专门进行算力效能技术研发的团队 ,并且下了一个断言: “占领算力效能的制高点,将成为头部团队在工业级深度学习2.0阶段算法继续创新突破的胜负手” 。由此,把算力提到了一个可以跟算法比肩、成为可以系统性进行研究和优化的新领域。当时思考后给出的 方法论是:将算力从原来只是被特定的系统架构要求达成的约束,释放为可以跟算法、系统架构一起联合优化的变量 。COLD这个工作,就是在这样的大背景下的一个具体落地。关于算力效能技术体系我在后面的第5小节会专门介绍。

图7:深度学习前/后,算力、算法与系统架构的协作关系
比较有意思的是,COLD这个粗排架构,很多人看不懂,最多的疑问是它除了算力上释放了红利外有啥优势。答案我前面已经给出:COLD是粗排算法体系可以有大的进展的最重要基础实施,是众多粗排算法要解决问题的快速迭代基础,这些问题包括:sample selection bias、数据循环、向精排模型的预估能力看齐还是向精排系统的排序能力看齐、要不要向召回延伸等等。懂的人自然会懂。
- 话题2:广告、推荐等算法体系的设计哲学
通常规模化的广告、推荐系统,都遵循召回粗排精排重排/混排/竞价机制这样的算法体系,有些甚至在召回和粗排中间还有更简单的海选模型做进一步的算力消耗和效果平衡的缓冲。考虑到整个算法链路都要围绕同一个目标进行优化,如广告系统的RPM最大化、电商推荐系统的GMV最大化等,这就要求所有的算法中间模块如召回、粗排等都遵循精排同样的候选集筛选规则,这种一致性我们在广告系统里面称之为竞价顺畅度,应该很容易理解。要保持这种前后算法模块逻辑的一致性,实际技术发展出来了两条截然不同的路径,我称之为两种不同的设计哲学。

图8:广告推荐算法体系的两种设计哲学
第一种设计哲学:城邦自治模式 。召回、粗排、精排等每个模块都按照自己对于全局一致性逻辑的理解,在平衡好集合规模、算力消耗、系统性能等约束的情况下独立迭代。例如广告系统的精排需要同时具备多种优化目标的模型预估和自动调价能力,那粗排就跟精排建设一致的能力,只是平衡点做些移动。这是目前占据上风的设计模式,我以前称之为CAP大法(copy-and-paste):把精排的模型在粗排做一遍复制和改良就好。当然这种设计很大程度是受历史技术发展的路径依赖所致。它不太容易犯错,缺点是会导致系统堆栈越来越长、各个模块拥兵自重,最后使得整个系统锁死、很难进一步迭代发展,更不用说突破。
第二种设计哲学:一盘棋模式 ,把整个算法体系路径做短、路径上的模块做宽。相比于城邦自治模式而言它追求模块间联动协同、统一听指挥。例如,在这种模式下粗排就不需要跟精排一样建立多目标预估和调价的能力,可以采用LTR的方式直接学习精排阶段的rank序,从而让粗排隐含地学习到精排的排序规则;相应地召回也不需要刻意地追求跟精排阶段一致的候选集筛选(排序)能力,而是在确保合理的分辨率情况下扩大供给后链路的召回集合规模,相信队友能够给你互补性。这个设计存在两方面的挑战:1. 打破了很多团队的组织划分方式,需要有比较强的背靠背组织力,同时还需要有强力的算法架构师通盘思考整个算法体系;2.短路径、能力互补,就意味着后链路的排序模块能力要超强,因为前置模块相当于战略性放弃了自身的排序能力,选择相信后链路,打好辅助位。同时,这种前后模块联动的模式对于系统的死锁效应如数据循环问题需要认真研究。不过,它的优势在于系统足够的灵活、单模块能力的溢出效应释放较为充分,单点突破能迅速带动整体提升,天花板更高。
目前,我们团队在验证第二种设计哲学的可行性。我个人的判断和偏好更倾向于它。
3. 精排技术
这是阿里展示广告团队的传统优势方向,比较多的工作都通过论文、演讲等对外分享过,大家应该有相对多的了解,知乎上也有挺多的解读。这里我就简略一些,介绍这些工作背后设计动力和逻辑,对照着最后我们研发成功、写在paper里面的方案,应该会有一些有趣的发现,同时也可能给大家带来一些新鲜的想法启示。

图9:阿里展示广告团队CTR主模型的发展轨迹(2016-2021)
图9是自2016年以来阿里展示广告团队CTR主模型的主要公开版本。说明两点:1. 这些主模型全部都是对应时间段在展示广告业务线全量上线、取得显著业务收益的模型,且我们的论文中每次都清楚地写着生产环境的A/B结果,绝不是一些喷子所谓的只发paper、根本不上线的炫技;2.虽然这些公开出来的模型并不是团队的全部家底,但主体的技术思路都有覆盖。
可以看到,2016-2020年我们持续在基于行为驱动的用户兴趣建模方向投入了重兵、也取得了不错的成绩。DIN/DIEN大家应该非常熟悉了,我在“互联网技术明珠”文章中也仔细介绍过,这里直接跳过,简单讲一下MIMN和SIM最新两代模型:
- 这两个模型的核心思考都是给CTR模型填充更大的信息输入,路径选择的是开垦淘宝储量极其丰富、可模型化挖掘的超长周期行为序列数据。这种长度达到数万规模的序列建模问题,学术界还没有解法,因此算法层面我们也是摸着石头过河;此外,数亿用户、单用户数万长度的行为数据对工程架构体系的挑战巨大,因此这两代模型研发的背后都涉及算法-工程co-design问题。尤其是每个模型的挑战都是独一无一的,在真正的模型出来之前工程团队也很难介入,算法同学需要兼具建模能力及系统设计能力;
- MIMN应用了memory network结构。最初的构思是希望摆脱掉DIN/DIEN attention式结构需要对每一个ad遍历用户所有历史行为的计算挑战(复杂度M*N,M是广告个数,N是用户行为个数),预先扫描用户的全部序列行为提取出兴趣点并存储起来,空间换时间,实际线上serving的时候就不用与ad侧做交叉遍历。这样的设计理论上可以容纳近乎无穷长度的行为序列数据。然而19年做出这个工作后不久,我就放弃了这条路径。设计出的解耦式UIC系统有点复杂、迭代不够灵活倒是次要原因,核心原因是数亿用户、每个用户的memory matrix参数规模在103量级、整个模型参数达到千亿量级,而memory参数的学习需要借助NTM范式read+write的方式进行forward/backward,我跟学术界的同行们交流,这种千亿参数规模的memory模型学术界难以想象、算法上很难继续往前走;
- SIM模型是我个人推荐的当前最优超长行为序列建模方案。之前老看到知乎上有人提及SIM模型跟UBR4CTR模型(上交伟楠组的工作)感觉很像,这个嗅觉很对,这里正好介绍下背后的故事。事实上这两个模型的确同源。2018年我在团队发起了一个AIR项目(阿里跟高校合作项目),邀请了伟楠团队作为高校方加入进来合作推进memory network在CTR领域的研发(合作成果后来发表了一篇HPMN学术论文),在开题报告讨论的时候我发散了一下,提出兴趣建模的终极目标是构建“一人一世界”模型:为每个用户基于其在淘宝的全部历史行为(很多用户使用淘宝历史长达10多年,行为序列长度超过10万)构建真正属于他的模型。memory net应该不是终极方案,一种理想的原型是用database将每一个用户的行为数据独立管理起来,建模时从db中查询就行,例如search就是一种可行的范式。当时这个话题引发了大家的热烈讨论,伟楠进一步发展了search的思路,提出可以引入RL来可控地引导search的过程,将其参数化。这个讨论埋下了火种,随后在AIR项目结束的1年后,我的团队跟伟楠团队各自沿着自己的强项、独立发展出了这种search-based的超长行为序列建模范式,且伟楠团队动作更快些(没有实际线上生产化的负担、算法探索先行),UBR4CTR的论文比SIM模型早了一点发出。SIM的纯算法我们也很早就研发成功了,但是要把SIM架构真正生产化,我们花了2/3甚至更长的时间,因此paper公开得晚一些。细心的读者对比两篇论文,可以看到同一种技术思想下,学术界思考和工业界思考非常明显的差异性,很有趣。
- 话说回来,SIM模型事实上否定了MIMN那种解耦ad*user遍历计算、预抽取user侧兴趣向量的方案,回归到attention式交叉访问的结构。只不过SIM跟DIN/DIEN有两个重大的区别:1. SIM的交叉访问是在原始输入侧而不是embedding之后;这背后是我对CTR模型的输入端建模这条路径思考的结果(下文详细介绍);2. SIM要handle每个用户104量级序列行为数据的建模,因此对行为序列数据的结构化存储和高效检索是关键技术。在SIM论文中我们给出了一种最简单的实现:基于淘系商品的category结构,对每一个用户的历史行为按照 {user, category} 行为item-list的kkv结构存储在分布式内存中;检索时对每一个ad用它属于的category加上user为key在这个kkv结构中查询,取出跟ad同类目的行为数据。这样操作后将长达数万的用户行为序列迅速缩减到几百的量级、达到DIN/DIEN擅长处理的序列规模。背后的思想非常直观:先用trigger将超长历史行为数据做一轮筛选挑出最相关的子序列,然后做精细化的兴趣建模。Naïve以及simple的特性使得SIM模型很受欢迎。据我所知,包括快手和小红书在内的不少公司都基于SIM拿到了不错的业务效果。
- 当然,不论是MIMN还是SIM,我们不要被具体的做法迷惑了视线、忘记了真正的目标。超长序列行为数据提供了极好的窗口,让我们有机会深度理解每一个用户,从而有机会为其构建属于他自己的模型,这是真正的个性化。SIM虽然给出了一条可行解,但离这个目标还有距离,一个设想的思路是联邦学习的方案:为每个用户训练独立的model,用户间通过联邦学习进行local和global之间的信息交互,保留单用户个性化的同时通过全局信息共享来提高单用户模型的泛化性。这种“一人一世界”模型我个人认为是即将来临的IOT时代重要的基础技术:每个人都能拥有一个高度私有化/个性化的virtual agent。
兴趣建模发展到今天,除了我们团队外业界也有非常多漂亮的工作。但大家都面临同样的问题:兴趣建模的边际收益越来越低了。如何突破这个困境,打造CTR模型技术的第二条增长曲线,是2019年底开始我一直在思考的命题。幸运的是,很快我找到了新的方向。
这里我分享下自己的思考路径:我们之前一直聚焦用户的序列行为挖掘,DIN/DIEN/MIMN/SIM等兴趣模型本质上是我们对 “用户兴趣” 这个物理概念进行的数学化解析,我称之为 “物理式先验建模” ;而除了兴趣建模外业界还有另外一个方向,如PNN、DeepFM、DCN等,这些模型也在特定的场景被广泛使用。相比兴趣模型而言这些模型本质上是基于人的先验认识,通过模型的结构设计捕捉 特征之间的"代数关系" ,这个流派我称之为 “代数式先验建模” 。只不过DeepFM等模型大都是在特征的embedding层之后进行特征的交叉关系刻画,其本质是固定了输入不变、在embedding空间刻画先验信息。我觉得这样的解法增益空间不够,核心是作用点要前置。
基于这样的思考,从2019年底开始,除了继续深度推进SIM这样的兴趣建模外我同时在团队中正式地开辟出来了“输入端建模”这个方向,方法论是:在模型最开始的输入层(embedding层之前的原始ID特征层),引入更多的差异化信号,设计更好的网络结构,给模型填充新的结构信息,提升模型的容量天花板。此时我不再如兴趣建模一样追求网络结构跟用户兴趣之间的“物理式”连接,转而沿着“代数式先验”的视角补充诸如特征间共现关系、特征的特异性、特征的层次结构关系、样本之间的关系等信息。要强调下:输入端建模不等于人工特征工程,差异点在于前者希望通过具备可学习性的参数化建模来捕捉代数信号,而不是人工穷举。可喜的是,2020年我前前后后砸了rank团队一小半的人力、终于搞出了声响,CAN模型就是我们摘到的第一颗桃子。
- 如周国瑞同学在“想为特征交互走一条新的路”一文中的分享,事实上我们团队对于输入侧的建模远不止CAN这一个探索。我一直对embedding结构耿耿于怀:它太粗暴,lookup table的方式使得集中了CTR模型99%以上参数量的embedding matrix学习很低效。从很早之前我就一直试着设计不一样的结构来更好地完成sparse id到dense representation这一过程的参数化,折腾了不少方案,但至今都没找到漂亮的解法。这让我对embedding充满了怨念:id不得不经过低效learning的embedding翻译后续的网络部件才能处理,而embedding又不太有什么意义,纯粹是data-driven的学习过程收敛出来的结果,且任意两次随机初始化的训练,embedding之间也很难有什么内在的泛化性联系。相反地,原始的sparse id本身有着确定性意义,或者说输入端蕴含的信息是确定的,只不过embedding这个翻译的codebook有随机性。为此,在推进输入端建模时我非常强烈地坚持了 在embedding之前“搞事情” ;
- 最初我对输入端建模的构思是:输入侧sparse ID之间有信息关联,比如淘宝体系中每一个商品的item id,它跟从属的shop id、category id等等都是有连接的,每一个用户的行为序列,又是由这些id list所构成,如图10所示。之前我们是直接把这些id当成独立的feature输入到模型作为用户的画像签名,期待模型能够从大量的数据里学习到id之间的关系。而实际情况是原有的CTR模型并不能很好地捕捉到其中的关联性。既然如此,我后退一步, 显式地告诉模型这些id之间的关系 ,这应该能够大大提升原始输入端的信息量,帮助模型更好地学习!方向确定了,具体怎么实施呢?我设计了两条路径:1. [终极路径] 用一个庞大的异构graph将id之间的联系刻画在其中,这个graph以及原有的sample一起输入给模型,比如将graph常驻训练框架的内存中,任何一条sample在进行训练时,先将对应的feature id去这个graph上游走一遍,获得补充信息,由于graph对所有的sample一致,这本质上在补充sample-wise的关联信息;2. [启发式路径] 不直接引入graph,基于graph预选定义一些白盒式结构,比如item-item的一阶关系、item-cate-item的二阶关系、item-shop-user-shop-item的更高阶关系等,把这些信号直接输入给模型。路径2看起来像是用户行为序列建模领域的特征交叉,只不过它更特别一些,是基于客观存在的id之间的关系图谱进行的交叉关系扩展。

图10:输入端用户行为id之间的结构关联示意图
- CAN模型的创造是项目组的杰作。最初输入端建模项目组对路径1和2都同时开展了工作,但路径1对训练系统需要的改造太大,进展不太顺利;反而是路径2更快、更容易拿到了成果,因为早在17年团队就尝试过直接进行用户行为item id跟广告对应的item id之间进行笛卡尔内积交叉,这个尝试到了2019年底我们大规模地研究输入端建模时依然是有效。这种交叉特征从路径2的视角来看,还只是非常简单的item-item的一阶关系。因此项目组最初想快点拿到业务收益,先把这个版本上线。但这种笛卡尔内积带来的特征膨胀,对系统整个链路的冲击是巨大的,上线很费劲。这个过程中大家开始认真讨论参数化的方案。“输入端笛卡尔内积为什么有效”、“embedding之后做交叉的模型比如DeepFM等却不行“”这些问题“想为特征交互走一条新的路”一文中有清晰的阐述,核心点是embedding之前交叉本质上是增加了独立的输入参数自由度,而embedding之后任意两个id已经被对应的embedding向量表征了,再做交叉只是对MLP的一种先验变形。我们设计参数化的方案,就是希望保留输入端新增自由度的同时,尽量缩减这个新自由度引入的参数膨胀问题。项目组同学们的创造力由此被激发、设计出了CAN模型的结构。
- 啰嗦一下,CAN这个模型的研发是非常 典型的技术创造范式 。于我而言,只是输入端建模这个战略方向上一直坚信、原始id层增加信息量和自由度的方案一直坚持,余下的就是给团队尽可能多的空间和时间;真正刺破那一层纸、给出最终方案的是充满灵性的团队年轻的同学们,他们的集体智慧是主角。可以说 这种集团军作战的模式是阿里展示广告rank方向近几年来取得成绩背后的核心组织力 。知乎上一直有各种夸张的解读,觉得像这样的团队校招进来的同学都得有一大把顶会论文才行。事实上包括我在内,团队绝大部分同学都是硕士毕业,在校期间也都没有特别好的学术建树。我们选拔同学的标准,是看同学的灵性、技术的想象力,以及对技术是否真心的热爱、能否坚持下来坐冷板凳。不少顶会论文一大把的同学,真正跟他深入聊下去,发现只是一纸论文,而没有自己独立的思考,这是不行的。Rank团队大部分公开的工作,主要的作者们都是毕业1-3年左右的年轻人。当然这背后资深同学带路也很关键,但更关键的是 参与过工业界这种集体创造且成功过后建立起来的巨大自信 ,这种自信在团队的新老队员之间的传承,是这个团队最强大的竞争力。
- CAN这个模型只是输入端建模的第一个里程碑工作(其实严格来讲,SIM也可以认为是输入端建模的一种方案,事实上最初SIM和CAN两个模型研发小组我也是安排在一起的,只不过SIM的确还是围绕着兴趣建模)。CAN只是一阶item-item关系的参数化方案,回到我最初对于CAN的两条路径设计,显然沿着CAN的视角出发,输入端建模还有非常多的可能性,这个方向我判断未来还会有较大的深耕空间,期待团队同学们未来继续创造出更多惊艳的工作!
跟CAN同一年,我们在“代数式先验建模”这个视角下还有另外一条路线在推进:从精细化建模的视角出发,显式地利用给定训练集中明显存在的先验知识,STAR论文是这个视角下的第一篇公开工作。STAR的着眼点非常具体:我们原来的模型是把所有小场景的样本合在一起训练,这样既省事、不用维护那么多的模型(人力有限),又能够聚合样本、对小场景模型的训练有好处。但显然每一个场景里面用户的兴趣习惯、场景分布都有差异性,背后存在空间。在大红利可见地不多的今天,我们开启了精细化建模的路径。MMoE跟我们团队18年发表的ESMM模型一样,都是MTL建模的一种典型范式,只不过在这种多场景问题中不是最优。核心挑战是如何能够让不同场景之间既共享一定的信息,同时又尽量能够有独立的表达。STAR给出了一种比较直接但有效的解法,具体细节请见STAR论文。事实上STAT开启的视角远比多场景建模宏大,它把我们对通用建模中一些细微的、先验认为具备特征间/样本间差异性的信息,通过对应的输入特征做分叉,对分叉的每一部分设计独立的网络结构,同时分叉点输入给共享的网络结构。这样就能巧妙地把domain knowledge变成网络结构、在输入侧通过某些特征维度增加自由度的形式引入。例如,多场景建模就是在场景特征上增加了自由度。
STAR之后,团队还有的后续工作,时机合适应该会公开发表的。不过可以想见,这种先验知识引入自由度的方式再往前发展,一定会适时地走向model-based,且切入的维度从feature-wise逐步走向sample-wise,尤其是后者,我已经陆续看到有一些零星的工作出来了,这个方向可能会产生一批优秀的工作,大家可以提前做一下思考。
到这里为止,我把精排CTR模型的主要脉络都介绍清楚了。对于现代的广告系统而言,精排当然不止CTR模型,以阿里展示广告为例,包括加购率、收藏率、成交率、浏览曝光率、吸粉率等很多的优化目标都需要建模。多目标建模这个体系早些年我们的工作其实开展得不多,原因跟广告系统的bidding技术发展密切相关。从模型角度看,之前广告系统主体并没有明显脱离CPC广告,因此我们的主要关注CTR建模,多目标建模只是零星地做了些投入。2018年当时纯粹是为了布局MTL技术,我们拿CVR建模做了个试点,后来写了一篇小短文,介绍了ESMM这个方案,没想到受到了不少的关注。中间不少同学来问我为啥没继续推进这个方向的工作,现在大家应该清楚原因了。2019-2020年间随着展示广告的业务形态剧烈地创新,自然涌现出了更多目标的建模需求;同时,广告主的出价方式也大规模走向了支持多目标的auto-bidding模式,CTR之外的多目标建模就凸显出重要性了。
2020年我们认真地成立了一个项目组(人手紧张,只有大约2.5个人力),系统性地推进了多目标建模技术的研发。其中研究得最多的是延迟建模这个方向,也取得了不少的成果,去年底将defer模型公开发表在KDD 2021上,感兴趣的同学可以读一读。考虑到本文的篇幅已经很长了,多目标这一块我就不再展开,留待团队的同学写一写更完整的思考给大家分享。
4. 广告的bidding与auction技术
这是广告区别于推荐技术的关键点之一,也是广告技术比较有魅力、但相对艰涩的地方。不过这一块我个人参与的不多,阿里展示广告的机制策略团队在这个方向有多年的积累和沉淀,近几年也把不少成果总结成论文公开出来,这里我帮团队打个广告、做个简单的索引,见图11。

图11:阿里展示广告机制策略的技术演进图
简言之,广告的机制策略要解决的问题是:如何在给定的商业化土地空间(也称ad-load)下做好三方服务:
1)用户侧:媒体坑位的接入策略,对应于smart AdLoad技术。典型的问题是信息流场景下如何进行自然结果与商业结果的混排;
2)广告主侧:如何精细化出价的技术,auto-bidding是当前的主流选型。典型的问题是如何充分leverage平台视角的数据,帮助广告主进行pv粒度的高效、自动出价;
3)广告平台侧:如何在充分满足用户侧体验及广告主诉求的情况下,设计良性的流量分配和扣费机制,引导整个广告博弈生态走向平台目标最大化。现代广告系统大都不再是单目标最优化,如电商广告平台一般需要同时兼顾平台收入、平台GMV等目标的综合最优化。
这三方策略优化涉及非常多的技术,每一个方向上阿里展示广告团队都有较深的积累。其中第三点是目前业界较为活跃、也比较有意思的方向,稍微讲两句。在这个方向上我们团队同样走在了技术的前沿,目前对外公开了两代 learning-based auction mechanism技术(下文简称LAM) ,其核心思想是打破基于人的先验、rule-based设计的auction机制,采用data-driven的方式,将auction机制中两个核心的函数——分配(allocation)和扣费(pricing)——用DNN模型参数化,然后通过learning的方式直接面向多目标综合最优结果设计reward来指导auction参数的寻优。这个过程中要对auction函数性态有特定的要求,以保障learning出来的auction机制符合激励兼容(Incentive Compatibility,IC)条件,具体请参见论文:
- Deep GSP: https://arxiv.org/abs/2012.02930
- Deep Neural Auction(简称DNA):https://arxiv.org/abs/2106.03593
当然这个话题要展开讲得足够透彻,有非常多的前置背景知识要交代清楚。团队的同学正在准备一份详细的技术专题,期待尽快问世。此外还有很多关键性的问题值得深度探讨,例如:同样是多目标最优化机制设计,LAM技术与古典的uGSP之间是什么关系、优缺点如何?LAM技术如何确保学习过程中机制的可控性,如何证明这种data-driven的机制能够收敛等等。
上面的1-4节花了非常多的笔墨阐述了在工业级深度学习2.0阶段,算法如何基于精排CTR模型构建的端到端建模方法体系以及AI基建能力,逐步地蔓延到召回、粗排、广告机制等模块,形成了广告全链路技术体系的整体前进。然而,这个过程绝不是仅依赖算法侧的工作。相比于精排CTR模型的well-define特性而言,召回、粗排等等都涉及如何克服超大规模的计算量难题以发挥这种全新且强大的算法能力,甚至是精排模型本身也深度面临对原有体系下算力和架构的新挑战。简言之,工业级深度学习2.0技术体系的构建,需要在算法之外对包括算力、架构等在内的技术全栈进行重构。下面的第5、6两节给出我们的实践和思考。
5. Beyond算法:算力效能技术
关于算力这个视角的思考,在上文第2节粗排技术中我已经详细阐述了其意义与方法论,这里就直奔主题,介绍从2018年以来我开始在团队布局、并且在随后的3年多时间里边思考、边实践,形成的三代算力效能技术体系。注意:虽然站在当下向前看,我们总结出了三代算力效能体系,但并不意味着在2018年的起点,我们就能够看得准确和清晰。事实上绝大多数的技术体系都是如此:边走边想、边想边实践,大家不用神话这个过程。
如站在2018年初我的预言一样,随着工业级深度学习的应用逐步步入深水区,算力效能这个方向受到了越来越多团队的重视,并且在算法的发展过程中多次扮演了关键先生。以阿里展示广告团队为例,核心主模型的年化算力以200%-300%的增速持续了5年时间,对应的算力需求增速显然高于GPU硬件升级带来的算力增速,2019年以前我们的主模型上线都需要非常痛苦的工程性能优化才能推全,且工程优化越来越艰难,算力效能技术建立之后,主模型的研发和全量上线基本是顺滑的,这背后算力效能居功至伟。以2020年为例,我们纯通过算力效能技术的成功研发就带来了超过90%的算力消耗下降,换句话说GPU机器数不变情况下,算力效能技术打开了10倍的模型复杂度空间,这是巨大的成就!2020年底的datafun年会,算力效能方向的主力创始同学姜碧野代表团队对外做过一个公开分享,比较详细地阐述了我们的技术发展路径 (感谢datafun的支持,特地将这篇付费文章免费公开出来)。其中第三代以个性化算力为内核驱动的柔性引擎系统升级,我在算力经济时代:阿里展示广告引擎的"柔性"变形之路一文中也做了详细的技术介绍。今年可喜地看到,美团外卖广告团队借鉴了个性化算力的思想以及我们提出的transformers柔性系统架构,在自己的业务场景将其落地,取得了可观的收益:
“一方面,在机器资源持平的情况下,CPM可以提升2.3%;另一方面,在业务收益持平的情况下,机器资源可以减少40%”
感兴趣的同学可以对照着这两个工作读一读,能看到一些共同的思考。文字能看到的内容我就不展开了,这里稍微再花点笔墨,追溯立项算力效能这个方向时的一些思辨,以及随后技术迭代过程中我的思考,应该有一些参考意义。
- 2018年在启动这个方向时,我们严肃地讨论过当时在CV界已经有点火热的模型压缩、剪枝等技术是不是直接应用过来就可以解决我们的问题,做过一轮调研后给出了否定的答案:CV模型跟广告推荐模型结构上有着很大的差异,广告推荐模型这种稀疏输入、99%参数集中在巨大的embedding table的特性,使得它对算力的消耗结构不同于CV模型;此外,当时CV领域关注较多的是如何减少model的大小使其可以装载在更小的嵌入式设备中;而广告推荐领域关注的是如何实打实地减少模型的算力消耗以及latency消耗,使其可以面对百万、千万量级的QPS计算时提供准确实时的inference服务。基于这种观察,我们把最初的算力效能重心限定在面向实时inference的模型效能优化,命名为 OFI(optimize-for-inference) 。跟OFI相对应的是OFT(optimize-for-training)技术,这一块我们直到今年(2021年)才调整为重点。因此,这里提及的算力效能技术,都是特指OFI技术。
- 第一代OFI技术,我们就是邯郸学步直接借鉴了CV领域的模型剪枝、低精度等。
- 不过很快我们就发现,对单点模型做这些变形,存在两个方面的问题:1. 算法的模型压缩跟工程实现以及硬件支持存在gap,如原则上二值化低精度模型拥有更强的算力空间,但不论是cuda计算还是GPU卡都不支持这种运算; 2. 算法侧对模型的剪枝等优化跟真正inference时追求的性能目标难以align,如模型的MLP层哪怕剪枝掉50%参数,最后模型的算力消耗可能也没太大的改变。这两个问题催生了我们进一步思考,形成了以algo-sys co-design为内核的第二代OFI技术。这里的co-design不仅仅是技术上,也包括了算法跟工程同学的分工。今天这种组织co-design方式已经深入到展示广告算法与工程同学的日常工作,成为了大家习惯的思考和工作模式,这是非常了不起的事情。当然,co-design的模式只解决了第二代OFI技术的一半难题,优化手段跟优化方向的align问题,直到2020年我们才解决了这个align问题,可以参见刚刚发表的APAS论文。
- 第二代OFI技术迭代在2019年取得了很多的成绩,不过我很快又意识到算力效能技术如果依然局限在对单点模型做算力优化,那天花板太低了。事实上算力不局限在model-inference这一个操作,在整个工程引擎运行过程中到处都流淌着算力。这一思考催生了我们的 第三代OFI算力效能技术:对每一个QPS请求都可以精细化地度量出算力消耗跟业务收益,从而在有限的机器资源下 “个性化”地对每一个pv进行算力的分配,以达成业务收益最大化 。这个思想迅速地在我们面前展开了一幅宏大的画卷:算力、算法和业务收益如同草原上奔腾的万马,我们在可测量目标的指引下,可以灵活地指挥整个马群的行动。充满了美感,不是吗!
算力效能技术体系的构建和发展,打开了一扇全新的技术大门。除了解决燃眉之急、为我们在工业级深度学习2.0阶段精排模型继续复杂化提供了动力外,更是点燃了召回和粗排技术,如第1、2两节已经介绍过的,催生了我们以算力消耗与算法效果的可控tradeoff为出发点研制成功的COLD、二向箔技术(细节翻看前文)。换句话说, 算力已经从被动优化的角色,转变为可以主动出击、驱动算法的迭代路径发生神奇分叉的源动力 。这种想象力驱动的技术创造,充满了无穷的魅力。相信随着对算力效能体系的进一步挖掘,这个领域将有机会发展成一门新兴的学科。一些基础性问题,如算力效能的benchmark数据集、性能度量metric、硬件-算力-算法三元关系的科学测算等,还需要进一步填充完整。
幸运的是,我在这个新兴学科的酝酿初期做出过一点点贡献。
6. Beyond算法:工程系统架构

图12:冰山一角
我在团队内、外分享时,经常讲这个观点:我们团队之所以能在算法模型、算力效能等技术上短时间内解锁非常多的漂亮工作,强大的工程基建扮演着重要角色,如同藏在水下的冰山主体一样。背后更本质的思考,是我们对可迭代性的持续追求:一个星期高效迭代100次模型的团队,比相同时间只能迭代10次的团队,生产力就是强10倍。下面我分算法模型生产(training体系)和算法模型服务(serving体系)两块工程体系做简要介绍。
6.1 流式AI训练引擎
在第二章“屠龙宝刀:工业级深度学习1.0的红利期”中已经介绍过,2016年在看到深度学习即将爆发的巨大威力后,我们自研并后来开源了工业级深度学习框架XDL,以解决自己迭代算法没有趁手武器的难题。然而XDL主流支持的还是批处理模式:模型一天一训练。2018年起,我进一步推进了训练架构向ODL(Online Deep Learning)转变。
最初的驱动力其实非常简单:团队包括生产和实验迭代的模型太多,18年的时候就超过了100个。批处理迭代模式下每训练一个模型都需要全量的样本处理和模型训练,这么多模型所消耗的资源实在吃不消。集团那几年也在极力地压缩每个财年的机器预算。因此给定有限的资源、解决算法的迭代性就变成了一个生死问题。从批处理走向增量处理或者流式处理就是必然的选择。增量处理可以认为是批处理的一个补丁版,更稳妥但天花板有限。我选择的是一步到位,全力推进了ODL技术体系的建设。最初在2018年的时候,我们先基于XDL的版本做了一些前置的特征与样本流程的streaming化改造,在2018、2019两年的双十一都取得了不错的效果,但问题是这种胶水式模式下迭代一个模型需要在非常多的系统之间切换,且迭代效率极低。不过这些探路也给后面的新ODL训练系统研发积攒了经验。
2019年双十一之后我构思、并且完成了全新的流式深度学习系统的原型设计,系统命名为Bernoulli(伯努利,致敬流体力学宗师)简称B站,希望能够成为团队新的算法迭代工作坊。跟XDL不同,Bernoulli并不着眼于底层的训练引擎本身,而是专注面向算法同学日常迭代的主要场景(特征+样本)做合理化的抽象,使得迭代的效率最高、资源的消耗率最低,底层则桥接任意的训练引擎,当然我们首选的是自研的XDL框架。换句话说,Bernoulli负责解决的是模型训练的外围工作,模型结构的修改还是放在了XDL中用python脚本直接编写。2020年初 Bernoulli研发上线,迅速成为了团队迭代的主阵地,甚至后面团队大部分的算法迭代都基于流式系统、不再需要批处理模式打底。原本我计划推动Bernoulli开源,可惜这个计划要流产了。
虽然在后续的逐步升级中,Bernoulli系统包含了非常多的有效组件,但两个最重要的设计理念,我认为是Bernoulli系统的精髓所在,其出发点都是服务于“迭代的效率最高、资源的消耗率最低”这个最高目标。
1)面向迭代模式的架构设计。见图13,我选择的是第二种架构。这种架构适合大量模型迭代的业务。
2)原子流抽象下的结构化范式。见图14。这是Bernoulli的内核。将流式环境下的样本拆解为一个个独立特征对应的原子流;任意一个模型的训练,只需要按需订阅特定的特征原子流,实时完成样本的拼接即可。

图13:两种ODL系统的架构对比

图14:结构化的流式数据范式
Bernoulli全量后对单个模型的资源利用率有着极大的降低,近乎完美地解决了我们数百个近TB量级模型的迭代问题。今年我们把Bernoulli系统总结成论文,刚刚发表,里面有更多的设计细节,感兴趣的同学可以读一读。
6.2 在线AI服务引擎
这里主要探讨算法模型在线服务的引擎部分,不是传统意义上支撑业务的流程引擎。更具体点说主要聚焦于召回和排序这两个模块。不过这涉及到非常多的业务特性背景,跳离业务很难讲清楚抽象背后的逻辑。但这样就超过了可以公开探讨的技术范畴,此处只好也先留白,待团队同学在合适的时机做一些总结、给大家做分享。不过可以剧透一下,与召回算法体系对应的是统一match-server架构设计;与排序算法体系对应的是统一ranker架构设计。这两个典型的AI服务引擎的设计,背后融入了大量的算法视角对未来技术发展走势的推演。还是那句话,AI基建能力建设着眼点是服务于未来1-3年的算法迭代体系,因此必需要能够判断清楚技术走向。
再啰嗦一句:在线AI服务引擎绝不仅是工程引擎同学们该关注的话题,算法工程师、尤其是算法架构师必须时刻关注这个架构体系与当前算法与算力技术发展的适配性。算法、算力与系统架构纳入整体视角一起考虑、设计和重构,本来就是工业级深度学习2.0阶段的思考核心。
7. 工业级深度学习2.0技术体系的关键词
在2019年撰写的“互联网技术明珠”文章末尾,我抛了一个问题:(业级深度学习1.0)下一阶段的关键词是什么?我想行文到此处,答案应该呼之欲出了:算法+算力+系统架构的全链路co-design重构,其本质是以深度学习为代表的先进算法驱动了技术全栈的系统性升级。
四、屠龙少年坠入深渊:暗夜降临
第三章“宝刀未老:工业级深度学习2.0的深水区跋涉”花了非常多的笔墨阐述了我们打造出来的第二增长曲线对应的技术体系,细节很多,但莫忘了我们的主题。到这里,我们已经完整地看到了深度学习之前的黑暗期、工业级深度学习1.0的红利期,以及2.0阶段的深水区这三个完整的技术周期面临的问题、大的技术趋势、以及我们交出的答卷。
现在的问题是,我们现在在哪?
答案有点沮丧:我们已经在工业级深度学习2.0的深水区走得很远,这一轮由深度学习引发的广告与推荐技术变革已经全方位地武装了整个技术链条,可见的大机会几乎被挖掘殆尽,我们即将步入新的黑暗期。这是技术的轮回周期,曾经的屠龙少年在深渊中跟恶龙相博过久后已然悄然变成了新的深渊恶龙,我们将逐步沉入暗夜,等待着新的、未知的革命性技术降临。
为了让读者对这个新阶段有更清晰的了解,我试着总结一些基本的特征:
1)data-driven、end-2-end learning的DL建模范式,已经被算法链路上几乎所有的模块所采用,且大的红利都已经被收割了多轮,甚至算力、系统、架构等都已经被算法驱动着完成了适配性升级;
2)技术的优化方向,关注点开始从踩住大的技术节点,转变为填充大厦的边角、精细化打磨;
3)绝大部分的单点技术优化都会陷入到x%、甚至0.x%(x是个位数)的边际效应区,很难靠单个模块的升级带来业务超过10%甚至更高的增长,且每一个技术点迭代的周期性明显拉长;
4)开始进入到多种技术组合寻找增量空间、迭代复杂度和链条逐渐增加,系统逐渐不堪重负的新阶段。
这些特征与5年前“浅层机器学习时代末期”的技术特征呈现了惊人的相似性。

图15:工业级深度学习技术的宏观发展周期(以阿里展示广告为例)
跳出微观,站在更大的尺度能看得更清楚一些。图15左图是Gartner公司著名的Hyper-Cycle曲线,右图则是以阿里展示广告团队为例解构初的工业级深度学习技术的宏观发展周期,显然我们触碰到了新的瓶颈。
那么灵魂拷问是,下一代革命性的技术体系是什么?在哪里?
很遗憾,我也无从得知。
不过要说清楚的是,即使当前属于新的技术暗夜期,并不意味着技术已经无法带来增长了。只是站在当下,有一些基本的判断要足够清醒:
1)深度学习已经从fancy的技术革命者沉淀为通用的、新的基础设施技术;
2)作为新的基建技术,它的优势被深度挖掘后,其劣势必然会被更多的看到、放大。就如同当年的浅层机器学习技术,2000年初被引入工业界时也是代表了先进生产力,而在2010-2015年末期阶段则累积了大量的技术债;
3)所谓的新技术暗夜期是相对头部公司/头部团队而言,不同阶段的公司或团队技术发展有其先后层次性,以我的观察而言,业界还有相当多的团队处于工业级深度学习1.0和2.0的发展区间内。
当然,哪怕是对于头部团队仍然还有很多的精细化空间可以挖掘,这一轮的技术变革才走过了短短5年,还有着非常多的细节要去填充。同时,在这个渐进的改良阶段,也还有一些可行的摸索方向,也许刺破这些迷雾后能够看到新的可能性。我这里抛两个发散的设想。
- 设想1:更彻底的端到端体系。
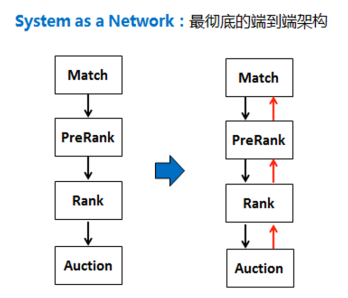
图16:广告算法全链路的DNN化
这个思路我跟团队分享过:在第三章第2节介绍粗排技术时已经提及我倾向于系统走向“一盘棋设计模式”,而这种模式的极致是形成一个完整的支持forward和backward一体的DNN网络:1)网络输入:用户的历史行为;2)网络输出:给定的推荐结果;3)Label:用户对推荐结果的实时反馈;4)隐层:召回、粗排、精排、auction等模块。换句话说,我们可以试着构建一个超大型的神经网络,将现有的算法全链路都包含在内,端到端地学习整个链路。它可能带来的好处是构建出既能互相协同与配合、且目标又充分一致的新算法链路,甚至在这种架构下算法链路里面的某一个模块我们都无需去关注它的物理意义,只需要关注模块的参数化形式、算力需求、业务需求对应的边界约束,剩下的就交给纯data-driven learning范式即可。
- 设想2:算法链路最前端的能力越过临界点后带来的全链路共振
以二向箔技术为引畅想下:如果召回模块被极致地武装上了足够复杂的DL模型进行全库计算的能力,从而使得召回出来的有效集合,不论是数量还是质量都跃升一个数量级,这可能带来全链路算法越过某个临界点,给后链路的排序和机制模块打开全新的空间,从而带来整个算法链路的共振。当然,这里臆想的成分多一些。核心的问题是当前各种rule-based的多通道启发式召回技术跟极致的全库复杂模型计算驱动的召回技术,其gap究竟有多大。我不清楚,但不妨碍可以试一试:对召回技术投入更强大的兵力进行爆破,捅一捅,看看能不能打开局面。
五、掩卷而思
每段旅行都有一个终点。以深度学习为突破点发起的这一轮轰轰烈烈的技术变革,波澜壮阔且又充满了层次感,让人惊叹,我将这段技术的发展过程做了个极简总结,见图17。

图17:工业级深度学习在广告推荐领域的发展周期简史
除却技术本身发展的宏大逻辑线条外,这段旅程还有一篇不得不提的华美乐章,那就是 国内互联网的技术自信 。作为早期的从业者,我经历过10多年前广告核心技术几被国外大厂垄断、高水平中文技术圈短缺的窘境;同样地,作为亲身参与的一员,我有幸在近5年工业级深度学习引发的技术变革期投身其中,跟团队一起做出了些许自己引以为豪的工作,这些微小的工作汇聚到众多国内同行的杰作洪流中,组成了一幅华人自研技术的壮丽图景,不知不觉间我们从技术跟随一路走到了今天的自主创新,虽然这些创新很微末,虽然还缺少很多底层的技术原创,但它做代表的意义是无比的巨大的,至少赢得了国外大厂技术的平视。再过头看这段历史,有种荡气回肠的痛快感:得益于国内互联网业务的规模性崛起、技术开源的思潮爆发、科技人才的不断涌现,中美互联网技术在很多领域已经几近可比肩。这段技术史的重大变局,伴随的是国内技术自信的稳固建立。2019年我跟几个朋友一起,以纯民间的力量发起了面向广告、推荐、搜索等高维稀疏数据场景下工业级深度学习实践的技术论坛:DLP-KDD workshop,如今已经坚持举办了第三届。虽然还很弱小,但workshop吸引了众多业界的资深同行加入。我们尽全力在打造一个高水平技术交流的舞台:让来自国内/国外、工业界/学术界的众多同行们可以畅所欲言,分享实践经验,交流最前沿进展。DLP-KDD workshop只是一个缩影,这种以华人为主、自由组织的国际顶会workshop、甚至顶会本身,越来越多地涌现在国际的舞台上,我想这是对这段波澜壮阔的国内互联网技术史最好的注解。
近些年每年团队春季实习招聘结束、年轻且优秀的同学们加入团队伊始,我都会给大家分享我杜撰出来的“三条路径爬山”故事: “人们发现了一座未知的巍峨高山,第一批人从山脚出发一路披荆斩棘、穿越茂密的丛林,稍有不慎就失足掉下被丛林掩盖的悬崖,最终杀出血路抵达顶峰的人十不存一,但存活下来的探险者们无比的骄傲,因为他们一路的拼杀是最美的风景,站在顶峰时开阔的视野只是这段风景的升华;第二批人随后出发,他们循着第一批人洒满血迹的路径,虽然依旧被一路的荆棘割伤,也会因稍加不慎掉入悬崖而丧命,但他们中大部分人还是顺利地抵达了顶峰、俯瞰来时的曲折。这些跟随者们也是骄傲的,他们追寻着探险者的足迹,虽然少了些许开拓性,但他们验证了探险者路线的可行性;随后旅游局的人看到了高山的价值,开始大规模投入、沿着前两批人的足迹铺设了登山栈道。第三批更多的游客随之闻风而来,他们拾阶而上,到达山巅时汗流浃背,看到满眼的大好河山时心生感慨,叫一声好” 。于我个人而言,不喜做技术的解释者,更偏好做技术的创造者。我给团队定义的技术使命是:勇于做探索者,在一些已有探索者出没的问题中也要毫不犹豫地力争做跟随者。最美的风景在途中,跨过深沟险壑达到顶峰时会收获强大的自信,这种自信是无比珍贵的。期待在下一轮的技术变局中,能看到身边涌现更多的探索者。而我,将会在新的toB战场继续探险。

