

基于华为云 ModelArts 深度学习算法的语音识别实践
【摘要】 前言利用新型的人工智能(深度学习)算法,结合清华大学开源语音数据集THCHS30进行语音识别的实战演练,让使用者在了解语音识别基本的原理与实战的同时,更好的了解人工智能的相关内容与应用。通过这个实践可以了解如何使用Keras和Tensorflow构建DFCNN的语音识别神经网络,并且熟悉整个处理流程,包括数据预处理、模型训练、模型保存和模型预测等环节。实践流程基础环境准备OBS准备Model...
前言
利用新型的人工智能(深度学习)算法,结合清华大学开源语音数据集THCHS30进行语音识别的实战演练,让使用者在了解语音识别基本的原理与实战的同时,更好的了解人工智能的相关内容与应用。通过这个实践可以了解如何使用Keras和Tensorflow构建DFCNN的语音识别神经网络,并且熟悉整个处理流程,包括数据预处理、模型训练、模型保存和模型预测等环节。
实践流程
- 基础环境准备
- OBS准备
- ModelArts应用
- 开始语音识别操作
- 开始语言模型操作
1.基础环境准备
在使用 ModelArts 进行 AI 开发前,需先完成以下基础操作哦(如有已完成部分,请忽略),主要分为4步(注册–>实名认证–>服务授权–>领代金券):
- 使用手机号注册华为云账号:点击注册
- 点此去完成实名认证,账号类型选"个人",个人认证类型推荐使用"扫码认证"。

- 点此进入 ModelArts 控制台数据管理页面,上方会提示访问授权,点击【服务授权】按钮,按下图顺序操作:

- 进入 ModelArts 控制台首页,如下图,点击页面上的"彩蛋",领取新手福利代金券!后续步骤可能会产生资源消耗费用,请务必领取。
以上操作,也提供了详细的视频教程,点此查看:ModelArts环境配置

基于深度学习算法的语音识别具体步骤
什么是OBS?
对象存储服务(Object Storage Service,OBS) 是一个基于对象的海量存储服务,为客户提供海量、安全、高可靠、低成本的数据存储能力,包括:创建、修改、删除桶,上传、下载、删除对象等。
2.OBS准备
1).将本地准备的data.zip和语音数据包data_thchs30.tar上传到OBS中,为后续步骤准备。
创建OBS桶将光标移动至左边栏,弹出菜单中选择“ 服务列表”->“ 存储”->“对象存储服务 OBS” ,如下图:

进去对象存储服务 OBS后,点击创建桶,配置参数如下:区域:华北-北京四,数据冗余存储策略:多AZ存储,桶名称:自定义(请记录,后续使用),存储类别:标准存储,桶策略:私有,默认加密:关闭,归档数据直读:关闭,点击“立即创建”,完成创建后跳转到桶列表,如下图所示:


2)创建AK/SK
- 登录华为云,在页面右上方单击**“控制台”**,进入华为云管理控制台。
**图1 **控制台入口
- 在控制台右上角的帐户名下方,单击**“我的凭证”,进入“我的凭证”**页面。
**图2 **我的凭证
- 在**“我的凭证”页面,选择“访问密钥>新增访问密钥”**,如图3所示。
**图3 **单击新增访问密钥
 - 填写该密钥的描述说明,单击**“确定”。根据提示单击“立即下载”**,下载密钥。
**图4 **新增访问密钥
- 密钥文件会直接保存到浏览器默认的下载文件夹中。打开名称为“credentials.csv”的文件,即可查看访问密钥(Access Key Id和Secret Access Key)。
3).安装OBS客户端
首先下载OBS工具到云服务器,在自己电脑打开命令行界面,执行如下命令:
mkdir /home/user/Desktop/data; cd /home/user/Desktop/data; wget https://obs-community.obs.cn-north-1.myhuaweicloud.com/obsutil/current/obsutil_linux_amd64.tar.gz
输入解压缩指令,并查看当前目录列表:
tar -zxf obsutil_linux_amd64.tar.gz; ls -l

执行如下指令配置OBS工具,操作说明:自己获取的密钥的AK/SK填入-i -k参数后面

执行如下查看对象列表指令,验证是否配置成功,指令如下:
./obsutil ls
配置成功结果如下图:

4)上传语音资料
执行如下指令下载实验相关资料:注:由于语音资料较大(7个多g),需要耐心等待
cd ../; wget https://sandbox-experiment-resource-north-4.obs.cn-north-4.myhuaweicloud.com/speech-recognition/data.zip; wget https://sandbox-experiment-resource-north-4.obs.cn-north-4.myhuaweicloud.com/speech-recognition/data_thchs30.tar

下载完毕,执行如下查看指令:
ll

输入以下指令,将刚刚下载好 的语音文件上传到创建的OBS桶nlpdemo中:
./obsutil_linux_amd64_5.*/obsutil cp ./data.zip obs://nlpdemo; ./obsutil_linux_amd64_5.*/obsutil cp ./data_thchs30.tar obs://nlpdemo
上传完毕后【大约60分钟,上传的速率较慢】 建议华为云优化一下OBS的上传速度 ,在华为云控制台依次选择“控制台”->“服务列表”->“ 存储”->“对象存储服务OBS”,进入服务界面,点击创建的桶名称nlpdemo进入详情页,于页面左侧选择“对象”,点击后于页面右侧可查看到刚传入的资料,

2.ModelArts应用
什么是ModelArts?
ModelArts是面向AI开发者的一站式开发平台,提供海量数据预处理及半自动化标注、大规模分布式训练、自动化模型生成及端-边-云模型按需部署能力,帮助用户快速创建和部署模型,管理全周期AI工作流。
- 创建Notebook在服务列表中找到并进入人工智能服务 ModelArts,然后点击ModelArts 页面中左侧的【开发环境】选项一点击【notebook】 进入notebook 页面。点击【创建】按钮进入创建页面,并按以下参数进行配置:名称:自定义,自动停止:自定义 12小时(在选择非[限时免费]规格后显示),
镜像:公共镜像:在第二页选择tensorflow1.13-cuda10.0-cudnn7-ubuntu18.0.4-GPU算法开发和训练基础镜像,预置AI引擎Tensorflow1.13.1,资源池:公共资源池,类型:CPU,规格:8核64GiB,存储配置:云硬盘(30GB)。
点击“下一步”->“提交”->“返回Notebook列表”,Notebook列表如下图所示:注:大约3分钟后状态由“启动中”变为“运行中”,可点击列表右上角的“刷新”查看最新状态。

3.开始语音识别操作
采用CNN+CTC的方式进行语音识别。
1)导入包
创建成功,返回NoteBook列表,等待状态变为“运行中”【约等待3分钟】,点击“打开”,进入NoteBook详情页。在页面中选择“TensorFlow-1.13.1”,如下图所示:

在新建的Python环境页面的输入框中,输入以下代码:
import moxing as mox
import numpy as np
import scipy.io.wavfile as wav
from scipy.fftpack import fft
import matplotlib.pyplot as plt
%matplotlib inline
import keras
from keras.layers import Input, Conv2D, BatchNormalization, MaxPooling2D
from keras.layers import Reshape, Dense, Lambda
from keras.optimizers import Adam
from keras import backend as K
from keras.models import Model
from keras.utils import multi_gpu_model
import os
import pickle
点击“代码旁边的小三角形”run,查看执行结果,如下图:

2)数据准备
继续在下方空白的输入框中输入以下代码,从上传到OBS的数据拷贝到当前目录:
注:下方框选的部分是之前创建的OBS桶名
点击“run”,查看执行结果,如下图:
current_path = os.getcwd()
mox.file.copy('s3://nlpdemo/data.zip', current_path+'/data.zip')
mox.file.copy('s3://nlpdemo/data_thchs30.tar', current_path+'/data_thchs30.tar')

继续在下方空白的输入框中输入以下代码,解压缩数据:
!unzip data.zip
!tar -xvf data_thchs30.tar

点击“run”,查看执行结果,如下图:

3)数据处理
继续在下方空白的输入框中输入以下代码,生成音频文件和标签文件列表:注:考虑神经网络训练过程中接收的输入输出。首先需要batch_size内数据具有统一的shape。格式为:[batch_size, time_step, feature_dim],然而读取的每一个sample的时间轴长都不一样,所以需要对时间轴进行处理,选择batch内最长的那个时间为基准,进行padding。这样一个batch内的数据都相同,就可以进行并行训练了。
source_file = 'data/thchs_train.txt'
def source_get(source_file):
train_file = source_file
label_data = []
wav_lst = []
with open(train_file,"r",encoding="utf-8") as f:
lines = f.readlines()
for line in lines:
datas = line.split("\t")
wav_lst.append(datas[0])
label_data.append(datas[1])
return label_data, wav_lst
label_data, wav_lst = source_get(source_file)
print(label_data[:10])
print(wav_lst[:10])

点击“run”,查看执行结果,如下图:

继续在下方空白的输入框中输入以下代码,进行label数据处理(为label建立拼音到id的映射,即词典):
def mk_vocab(label_data):
vocab = []
for line in label_data:
line = line.split(' ')
for pny in line:
if pny not in vocab:
vocab.append(pny)
vocab.append('_')
return vocab
vocab = mk_vocab(label_data)
def word2id(line, vocab):
return [vocab.index(pny) for pny in line.split(' ')]
label_id = word2id(label_data[0], vocab)
print(label_data[0])
print(label_id)

点击“run”,查看执行结果,如下图:

继续在下方空白的输入框中输入以下代码,进行音频数据处理:
def compute_fbank(file):
x=np.linspace(0, 400 - 1, 400, dtype = np.int64)
w = 0.54 - 0.46 * np.cos(2 * np.pi * (x) / (400 - 1) )
fs, wavsignal = wav.read(file)
time_window = 25
window_length = fs / 1000 * time_window
wav_arr = np.array(wavsignal)
wav_length = len(wavsignal)
range0_end = int(len(wavsignal)/fs*1000 - time_window) // 10
data_input = np.zeros((range0_end, 200), dtype = np.float)
data_line = np.zeros((1, 400), dtype = np.float)
for i in range(0, range0_end):
p_start = i * 160
p_end = p_start + 400
data_line = wav_arr[p_start:p_end]
data_line = data_line * w
data_line = np.abs(fft(data_line))
data_input[i]=data_line[0:200]
data_input = np.log(data_input + 1)
#data_input = data_input[::]
return data_input
fbank = compute_fbank(wav_lst[0])
print(fbank.shape)
点击“run”,查看执行结果,如下图:


继续在下方空白的输入框中输入以下代码,生成数据生成器:
total_nums = 10000
batch_size = 4
batch_num = total_nums // batch_size
from random import shuffle
shuffle_list = list(range(10000))
shuffle(shuffle_list)
def get_batch(batch_size, shuffle_list, wav_lst, label_data, vocab):
for i in range(10000//batch_size):
wav_data_lst = []
label_data_lst = []
begin = i * batch_size
end = begin + batch_size
sub_list = shuffle_list[begin:end]
for index in sub_list:
fbank = compute_fbank(wav_lst[index])
fbank = fbank[:fbank.shape[0] // 8 * 8, :]
label = word2id(label_data[index], vocab)
wav_data_lst.append(fbank)
label_data_lst.append(label)
yield wav_data_lst, label_data_lst
batch = get_batch(4, shuffle_list, wav_lst, label_data, vocab)
wav_data_lst, label_data_lst = next(batch)
for wav_data in wav_data_lst:
print(wav_data.shape)
for label_data in label_data_lst:
print(label_data)
lens = [len(wav) for wav in wav_data_lst]
print(max(lens))
print(lens)
def wav_padding(wav_data_lst):
wav_lens = [len(data) for data in wav_data_lst]
wav_max_len = max(wav_lens)
wav_lens = np.array([leng//8 for leng in wav_lens])
new_wav_data_lst = np.zeros((len(wav_data_lst), wav_max_len, 200, 1))
for i in range(len(wav_data_lst)):
new_wav_data_lst[i, :wav_data_lst[i].shape[0], :, 0] = wav_data_lst[i]
return new_wav_data_lst, wav_lens
pad_wav_data_lst, wav_lens = wav_padding(wav_data_lst)
print(pad_wav_data_lst.shape)
print(wav_lens)
def label_padding(label_data_lst):
label_lens = np.array([len(label) for label in label_data_lst])
max_label_len = max(label_lens)
new_label_data_lst = np.zeros((len(label_data_lst), max_label_len))
for i in range(len(label_data_lst)):
new_label_data_lst[i][:len(label_data_lst[i])] = label_data_lst[i]
return new_label_data_lst, label_lens
pad_label_data_lst, label_lens = label_padding(label_data_lst)
print(pad_label_data_lst.shape)
print(label_lens)
代码执行成功,如下图:

执行结果输出如下图:

继续在下方空白的输入框中输入以下代码,点击“run”运行,生成用于训练格式的数据生成器(此段代码无输出):

4)模型搭建
继续输入以下代码:说明:训练输入为时频图,标签为对应的拼音标签,搭建语音识别模型,采用了 **CNN+CTC **的结构。
def conv2d(size):
return Conv2D(size, (3,3), use_bias=True, activation='relu',
padding='same', kernel_initializer='he_normal')
def norm(x):
return BatchNormalization(axis=-1)(x)
def maxpool(x):
return MaxPooling2D(pool_size=(2,2), strides=None, padding="valid")(x)
def dense(units, activation="relu"):
return Dense(units, activation=activation, use_bias=True, kernel_initializer='he_normal')
def cnn_cell(size, x, pool=True):
x = norm(conv2d(size)(x))
x = norm(conv2d(size)(x))
if pool:
x = maxpool(x)
return x
def ctc_lambda(args):
labels, y_pred, input_length, label_length = args
y_pred = y_pred[:, :, :]
return K.ctc_batch_cost(labels, y_pred, input_length, label_length)
class Amodel():
"""docstring for Amodel."""
def __init__(self, vocab_size):
super(Amodel, self).__init__()
self.vocab_size = vocab_size
self._model_init()
self._ctc_init()
self.opt_init()
def _model_init(self):
self.inputs = Input(name='the_inputs', shape=(None, 200, 1))
self.h1 = cnn_cell(32, self.inputs)
self.h2 = cnn_cell(64, self.h1)
self.h3 = cnn_cell(128, self.h2)
self.h4 = cnn_cell(128, self.h3, pool=False)
# 200 / 8 * 128 = 3200
self.h6 = Reshape((-1, 3200))(self.h4)
self.h7 = dense(256)(self.h6)
self.outputs = dense(self.vocab_size, activation='softmax')(self.h7)
self.model = Model(inputs=self.inputs, outputs=self.outputs)
def _ctc_init(self):
self.labels = Input(name='the_labels', shape=[None], dtype='float32')
self.input_length = Input(name='input_length', shape=[1], dtype='int64')
self.label_length = Input(name='label_length', shape=[1], dtype='int64')
self.loss_out = Lambda(ctc_lambda, output_shape=(1,), name='ctc')\
([self.labels, self.outputs, self.input_length, self.label_length])
self.ctc_model = Model(inputs=[self.labels, self.inputs,
self.input_length, self.label_length], outputs=self.loss_out)
def opt_init(self):
opt = Adam(lr = 0.0008, beta_1 = 0.9, beta_2 = 0.999, decay = 0.01, epsilon = 10e-8)
#self.ctc_model=multi_gpu_model(self.ctc_model,gpus=2)
self.ctc_model.compile(loss={'ctc': lambda y_true, output: output}, optimizer=opt)
am = Amodel(len(vocab))
am.ctc_model.summary()

点击“run”,执行结果如下图:

**5)训练模型 **
继续输入以下代码创建语音识别模型:
total_nums = 100
batch_size = 20
batch_num = total_nums // batch_size
epochs = 8
source_file = 'data/thchs_train.txt'
label_data,wav_lst = source_get(source_file)
vocab = mk_vocab(label_data)
vocab_size = len(vocab)
print(vocab_size)
shuffle_list = list(range(100))
am = Amodel(vocab_size)
for k in range(epochs):
print('this is the', k+1, 'th epochs trainning !!!')
#shuffle(shuffle_list)
batch = data_generator(batch_size, shuffle_list, wav_lst, label_data, vocab)
am.ctc_model.fit_generator(batch, steps_per_epoch=batch_num, epochs=1)

执行结果如下图【大约需要11分钟,如果需要更好效果可以调整参数epochs为50次】:
)
6)保存模型
将训练模型保存到OBS中。继续输入如下代码(此段代码无输出):操作说明:用创建的OBS桶名填写参数
am.model.save("asr-model.h5")
with open("vocab","wb") as fw:
pickle.dump(vocab,fw)
mox.file.copy("asr-model.h5", 's3://nlpdemo/asr-model.h5')
mox.file.copy("vocab", 's3://nlpdemo/vocab')

7)测试模型
继续输入如下代码,点击“run”运行,用以导入包及加载模型和数据(此段代码无输出):
#导入包
import pickle
from keras.models import load_model
import os
import tensorflow as tf
from keras import backend as K
import numpy as np
import scipy.io.wavfile as wav
from scipy.fftpack import fft
#加载模型和数据
bm = load_model("asr-model.h5")
with open("vocab","rb") as fr:
vocab_for_test = pickle.load(fr)

继续输入如下代码,点击“run”运行,获取测试数据(此段代码无输出):
def wav_padding(wav_data_lst):
wav_lens = [len(data) for data in wav_data_lst]
wav_max_len = max(wav_lens)
wav_lens = np.array([leng//8 for leng in wav_lens])
new_wav_data_lst = np.zeros((len(wav_data_lst), wav_max_len, 200, 1))
for i in range(len(wav_data_lst)):
new_wav_data_lst[i, :wav_data_lst[i].shape[0], :, 0] = wav_data_lst[i]
return new_wav_data_lst, wav_lens
#获取信号的时频图
def compute_fbank(file):
x=np.linspace(0, 400 - 1, 400, dtype = np.int64)
w = 0.54 - 0.46 * np.cos(2 * np.pi * (x) / (400 - 1) ) # 汉明窗
fs, wavsignal = wav.read(file)
# wav波形 加时间窗以及时移10ms
time_window = 25 # 单位ms
window_length = fs / 1000 * time_window # 计算窗长度的公式,目前全部为400固定值
wav_arr = np.array(wavsignal)
wav_length = len(wavsignal)
range0_end = int(len(wavsignal)/fs*1000 - time_window) // 10 # 计算循环终止的位置,也就是最终生成的窗数
data_input = np.zeros((range0_end, 200), dtype = np.float) # 用于存放最终的频率特征数据
data_line = np.zeros((1, 400), dtype = np.float)
for i in range(0, range0_end):
p_start = i * 160
p_end = p_start + 400
data_line = wav_arr[p_start:p_end]
data_line = data_line * w # 加窗
data_line = np.abs(fft(data_line))
data_input[i]=data_line[0:200] # 设置为400除以2的值(即200)是取一半数据,因为是对称的
data_input = np.log(data_input + 1)
#data_input = data_input[::]
return data_input
def test_data_generator(test_path):
test_file_list = []
for root, dirs, files in os.walk(test_path):
for file in files:
if file.endswith(".wav"):
test_file = os.sep.join([root, file])
test_file_list.append(test_file)
print(len(test_file_list))
for file in test_file_list:
fbank = compute_fbank(file)
pad_fbank = np.zeros((fbank.shape[0]//8*8+8, fbank.shape[1]))
pad_fbank[:fbank.shape[0], :] = fbank
test_data_list = []
test_data_list.append(pad_fbank)
pad_wav_data, input_length = wav_padding(test_data_list)
yield pad_wav_data
test_path ="data_thchs30/test"
test_data = test_data_generator(test_path)

继续输入以下代码进行测试:
def decode_ctc(num_result, num2word):
result = num_result[:, :, :]
in_len = np.zeros((1), dtype = np.int32)
in_len[0] = result.shape[1];
r = K.ctc_decode(result, in_len, greedy = True, beam_width=10, top_paths=1)
r1 = K.get_value(r[0][0])
r1 = r1[0]
text = []
for i in r1:
text.append(num2word[i])
return r1, text
for i in range(10):
#获取测试数据
x = next(test_data)
#载入训练好的模型,并进行识别语音
result = bm.predict(x, steps=1)
#将数字结果转化为拼音结果
_, text = decode_ctc(result, vocab_for_test)
print('文本结果:', text)

点击“run”,执行成功如下图所示:.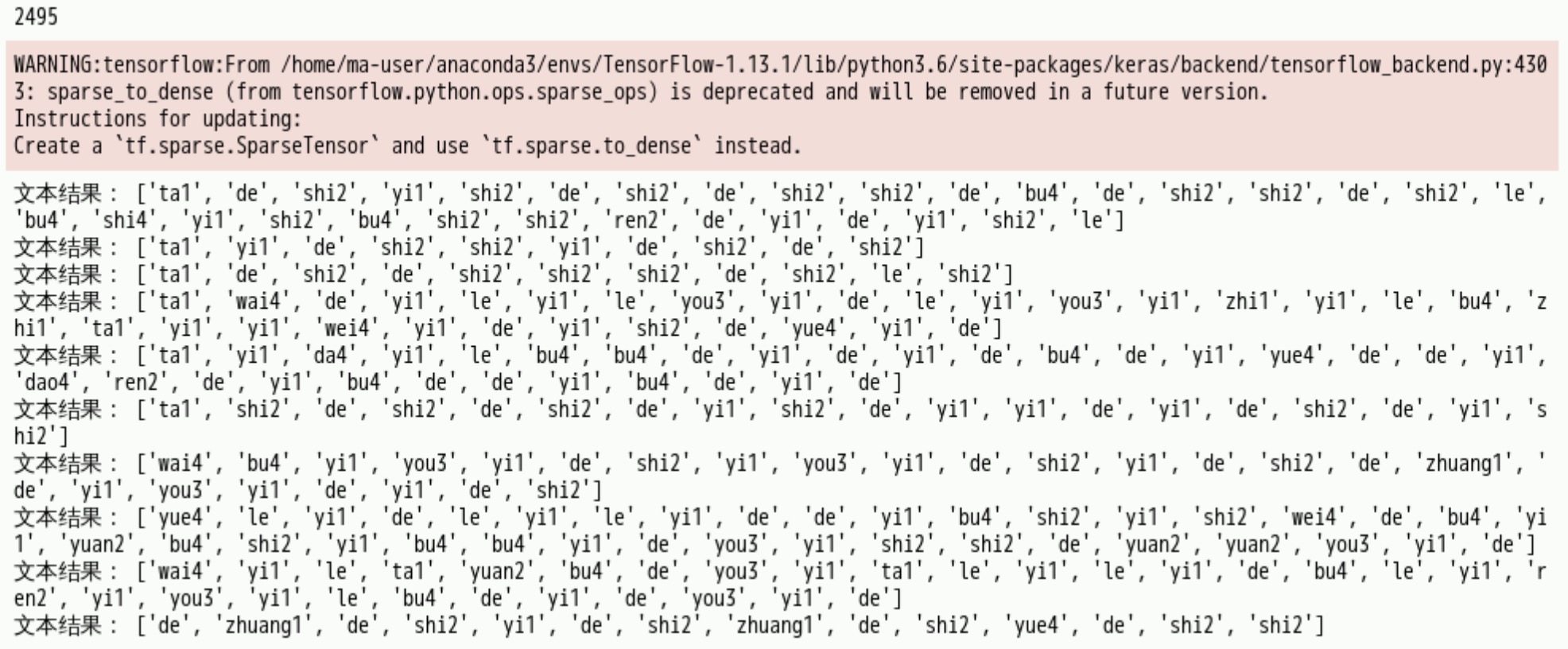
4.开始语言模型操作
训练语言模型是采用捕捉特征能力更强的 Transformer ,创建基于自注意力机制的语言模型,在实验的过程中会跟大家介绍具体的实现步骤。
1)导入包
继续输入如下代码,点击“run”运行,导入相关包(此段代码无输出):
from tqdm import tqdm
import tensorflow as tf
import moxing as mox
import numpy as np

2)数据处理
继续输入如下代码,点击“run”运行:
with open("data/zh.tsv", 'r', encoding='utf-8') as fout:
data = fout.readlines()[:10000]
inputs = []
labels = []
for i in tqdm(range(len(data))):
key, pny, hanzi = data[i].split('\t')
inputs.append(pny.split(' '))
labels.append(hanzi.strip('\n').split(' '))
print(inputs[:5])
print()
print(labels[:5])
def get_vocab(data):
vocab = ['<PAD>']
for line in tqdm(data):
for char in line:
if char not in vocab:
vocab.append(char)
return vocab
pny2id = get_vocab(inputs)
han2id = get_vocab(labels)
print(pny2id[:10])
print(han2id[:10])
input_num = [[pny2id.index(pny) for pny in line] for line in tqdm(inputs)]
label_num = [[han2id.index(han) for han in line] for line in tqdm(labels)]
#获取batch数据
def get_batch(input_data, label_data, batch_size):
batch_num = len(input_data) // batch_size
for k in range(batch_num):
begin = k * batch_size
end = begin + batch_size
input_batch = input_data[begin:end]
label_batch = label_data[begin:end]
max_len = max([len(line) for line in input_batch])
input_batch = np.array([line + [0] * (max_len - len(line)) for line in input_batch])
label_batch = np.array([line + [0] * (max_len - len(line)) for line in label_batch])
yield input_batch, label_batch
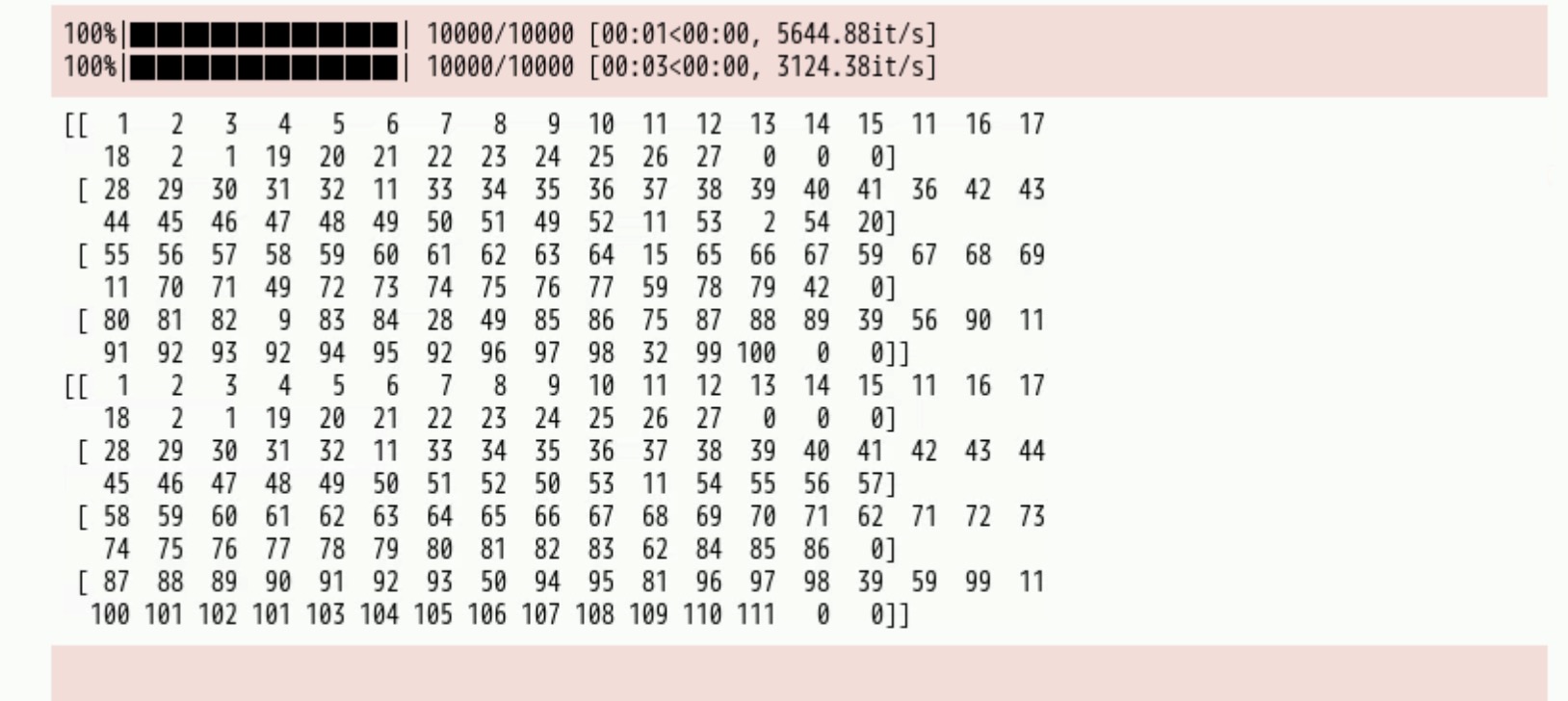
batch = get_batch(input_num, label_num, 4)
input_batch, label_batch = next(batch)
print(input_batch)
print(label_batch)

执行成功结果如下图:
3)模型搭建
模型采用self-attention的左侧编码器 ,如下图:
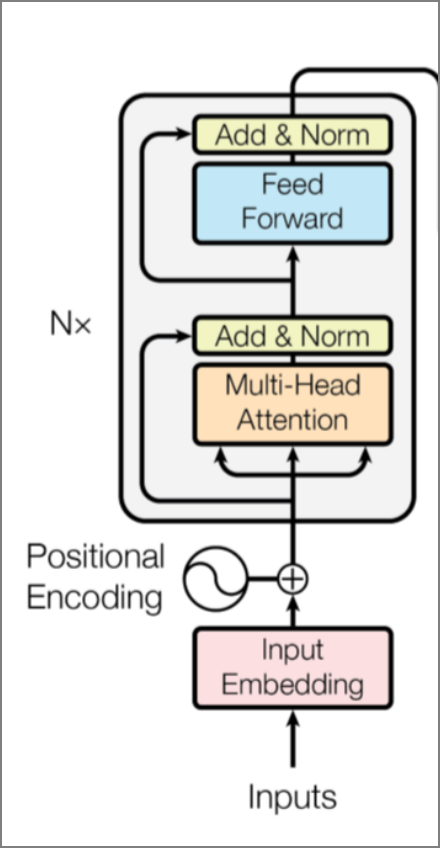
继续输入如下代码,点击“run”运行,用以实现图片结构中的layer norm层(代码无输出):
#layer norm层
def normalize(inputs,
epsilon = 1e-8,
scope="ln",
reuse=None):
with tf.variable_scope(scope, reuse=reuse):
inputs_shape = inputs.get_shape()
params_shape = inputs_shape[-1:]
mean, variance = tf.nn.moments(inputs, [-1], keep_dims=True)
beta= tf.Variable(tf.zeros(params_shape))
gamma = tf.Variable(tf.ones(params_shape))
normalized = (inputs - mean) / ( (variance + epsilon) ** (.5) )
outputs = gamma * normalized + beta
return outputs

继续输入如下代码,点击“run”运行,以实现图片结构中的embedding层(代码无输出):
def embedding(inputs,
vocab_size,
num_units,
zero_pad=True,
scale=True,
scope="embedding",
reuse=None):
with tf.variable_scope(scope, reuse=reuse):
lookup_table = tf.get_variable('lookup_table',
dtype=tf.float32,
shape=[vocab_size, num_units],
initializer=tf.contrib.layers.xavier_initializer())
if zero_pad:
lookup_table = tf.concat((tf.zeros(shape=[1, num_units]),
lookup_table[1:, :]), 0)
outputs = tf.nn.embedding_lookup(lookup_table, inputs)
if scale:
outputs = outputs * (num_units ** 0.5)
return outputs

继续输入如下代码,点击“run”运行,以实现multihead层(此段代码无输出):
def multihead_attention(emb,
queries,
keys,
num_units=None,
num_heads=8,
dropout_rate=0,
is_training=True,
causality=False,
scope="multihead_attention",
reuse=None):
with tf.variable_scope(scope, reuse=reuse):
# Set the fall back option for num_units
if num_units is None:
num_units = queries.get_shape().as_list[-1]
# Linear projections
Q = tf.layers.dense(queries, num_units, activation=tf.nn.relu) # (N, T_q, C)
K = tf.layers.dense(keys, num_units, activation=tf.nn.relu) # (N, T_k, C)
V = tf.layers.dense(keys, num_units, activation=tf.nn.relu) # (N, T_k, C)
# Split and concat
Q_ = tf.concat(tf.split(Q, num_heads, axis=2), axis=0) # (h*N, T_q, C/h)
K_ = tf.concat(tf.split(K, num_heads, axis=2), axis=0) # (h*N, T_k, C/h)
V_ = tf.concat(tf.split(V, num_heads, axis=2), axis=0) # (h*N, T_k, C/h)
# Multiplication
outputs = tf.matmul(Q_, tf.transpose(K_, [0, 2, 1])) # (h*N, T_q, T_k)
# Scale
outputs = outputs / (K_.get_shape().as_list()[-1] ** 0.5)
# Key Masking
key_masks = tf.sign(tf.abs(tf.reduce_sum(emb, axis=-1))) # (N, T_k)
key_masks = tf.tile(key_masks, [num_heads, 1]) # (h*N, T_k)
key_masks = tf.tile(tf.expand_dims(key_masks, 1), [1, tf.shape(queries)[1], 1]) # (h*N, T_q, T_k)
paddings = tf.ones_like(outputs)*(-2**32+1)
outputs = tf.where(tf.equal(key_masks, 0), paddings, outputs) # (h*N, T_q, T_k)
# Causality = Future blinding
if causality:
diag_vals = tf.ones_like(outputs[0, :, :]) # (T_q, T_k)
tril = tf.contrib.linalg.LinearOperatorTriL(diag_vals).to_dense() # (T_q, T_k)
masks = tf.tile(tf.expand_dims(tril, 0), [tf.shape(outputs)[0], 1, 1]) # (h*N, T_q, T_k)
paddings = tf.ones_like(masks)*(-2**32+1)
outputs = tf.where(tf.equal(masks, 0), paddings, outputs) # (h*N, T_q, T_k)
# Activation
outputs = tf.nn.softmax(outputs) # (h*N, T_q, T_k)
# Query Masking
query_masks = tf.sign(tf.abs(tf.reduce_sum(emb, axis=-1))) # (N, T_q)
query_masks = tf.tile(query_masks, [num_heads, 1]) # (h*N, T_q)
query_masks = tf.tile(tf.expand_dims(query_masks, -1), [1, 1, tf.shape(keys)[1]]) # (h*N, T_q, T_k)
outputs *= query_masks # broadcasting. (N, T_q, C)
# Dropouts
outputs = tf.layers.dropout(outputs, rate=dropout_rate, training=tf.convert_to_tensor(is_training))
# Weighted sum
outputs = tf.matmul(outputs, V_) # ( h*N, T_q, C/h)
# Restore shape
outputs = tf.concat(tf.split(outputs, num_heads, axis=0), axis=2 ) # (N, T_q, C)
# Residual connection
outputs += queries
# Normalize
outputs = normalize(outputs) # (N, T_q, C)
return outputs


