

搜广推精排难点之排序位置偏置
一、前言
在搜广推场景中排序模块的训练数据来源都是从系统埋点产生的日志文件中提取出来的,但是无论是搜广推哪个场景基本上都是存在位置偏置的,一般人的使用习惯基本是看推荐或者搜索的前几条或者前几页内容,我们后台能拿到的数据会有以下几种,曝光之后点击,曝光之后未点击,未曝光,一般有些公司做法会将曝光后点击样本作为正样本,曝光之后未点击作为负样本。这样做有个极大弊端,会出现未曝光的样本永远也推不上产生不了数据,而且未曝光样本未必比推在前面的样本内容差,所以推送位置也极大影响了推荐的效果,只要在展示场景中都会出现这一问题。这样推荐在前面的样本就会形成马太效应,推送会越来越频繁,后面的样本基本就没有机会展示给用户看。如何较好的缓解这种位置偏差,来更好地处理业界棘手的难题。
二、业界尝试过的方案
马蜂窝推荐排序
方案一(位置作为特征):马蜂窝推荐排序模型是CTR预估模型,它的训练样本是所有用户的曝光点击历史。为了消除位置偏差,提高模型的预测准确率,可以在模型训练的时候,将位置信息作为训练特征之一。 CTR模型
CTR模型
由于展示位置是在模型排序之后,模型进行预测的时候,无法获得展示位置。这时候可以使用默认值来代替位置特征。默认值由离线测试的AUC和线上AB测试最终确定。由于模型训练和预测时的使用的特征不同,该方案线上表现一般:用户点击率降低 0.3%,用户人均点击篇数提升0.2%,内容曝光提升0.1%,内容点击率降低0.1%。
方案二(逆倾向样本加权):逆倾向样本加权Inverse Propensity Weighting(IPW)被学术界广泛研究,IPW的核心思想在于,在得到每个样本的倾向性评分后,利用倾向性评分对样本重新加权。
马蜂窝使用基于点击率的逆倾向样本加权,具体做法是:统计马蜂窝推荐场景下所有的曝光点击信息,计算不同展示位置处的平均点击率,结果如图5所示。使用平滑后的点击率作为倾向性评分,对训练样本进行加权。使用带权样本训练排序模型,并用于线上预测。实验前两天内容点击率相对提升约6%,后面逐渐下降,正负波动明显。 马蜂窝线上ctr变化图
马蜂窝线上ctr变化图
方案三(基于EM模型消除位置偏差): EM算法获取位置权重
EM算法获取位置权重 马蜂窝位置对应的权重
马蜂窝位置对应的权重
计算出的位置能力分别应用于排序模型的训练特征部分和样本权重部分。
在训练特征部分,原来的特征中有很多点击率特征,马蜂窝对点击率特征重新处理,转换后的点击等于真实点击除以位置能力,转换后的点击率等于转换后的点击量除以曝光数量。 新ctr数据和新label
新ctr数据和新label
在样本权重部分,马蜂窝使用位置能力的倒数来代替原来的训练样本样本权重。马蜂窝每天基于EM模型生成的新的位置能力,该位置能力作用于排序模型后,对线上提升明显:用户点击率提升 2.1%,用户人均点击篇数提升4.5%,内容曝光提升1.9%,内容点击率提升3.3%。
知乎搜索排序
方案一(降低 Top 位置的样本权重):
既然 Top 位置更容易受到位置偏差的影响, 那么就降低头部样本的权重 。 至于样本权重的确定,尝试过两种方案:
根据点击模型预估每个位置的权重, 预估出来的结果可能是第一位 0.7 然后一直增加, 到第五位是 0.9 通过模型在训练的过程中自动学习权重但是这种方案上线之后都没有正向效果 。
方案二(对 Position bias 建模):
用户实际点击 = 真实点击率+ Position Bias 另一种思路就是考虑 Position Bias 的情况下, 重新对用户点击进行建模 。既然 用户点击是由文档的真实点击率和文档的展示位置共同决定的, 那就将这两部分 分 开 预 测, 用 文 档 的 展 示 位 置 作 为 特 征 通 过 一 个 独 立 的 shallow tower 对 Position Bias 进行建模[3], 将其他的 Query 和 Doc 本身的特征输入主模型 结构建模文档的真实点击率, 将两部分分数相加来预测用户点击 。在线预测时 , 只需考虑真实点击率的部分 。另外在训练的时候有两点需要注意, 一个是最好在 shallow tower 的 部 分 加 一 些 dropout 防 止 模 型 对 Position Bias 的 过 度 依 赖, 另一个是只有点击目标会受到位置偏差的影响, 所以只需要在点击目标上应 用这个策略, 在转化类目标上则无需这种处理 。这一版的策略上线对点击比带来了显著的提升 。
华为
方案一(PAL框架):
本文提出的消除位置偏置信息的框架称为Position-bias Aware Learning framework (PAL) 。其基于如下的假设,即用户点击广告的概率由两部分组成:广告被用户看到的概率和用户看到广告后,点击广告的概率。 点击广告的概率
点击广告的概率
该假设可进一步进行化简,首先,用户是否看到广告只跟广告的位置有关系;其次,用户看到广告后,是否点击广告与广告的位置无关。此时公式可写作: 化简公式
化简公式
基于该假设,就可以分开建模,PAL的框架如下图所示: PAL训练推理流程
PAL训练推理流程
可以看到,两个模块是联合进行训练的,如果分开进行优化,两个模块的训练目标不同,可能导致整个的系统是次优化的。
损失函数采用交叉熵损失: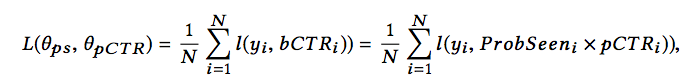 loss公式
loss公式
这里再说一下,论文中并没有给出训练位置信息的模块所使用的特征,可以参考youtube论文中的思路,加入位置特征和上下文特征来训练。
不过马蜂窝在线上尝试过此方案,模型训练时同时训练ProbSeen和pCTR部分,线上预测的时候只使用pCTR部分。由于位置信息只作用在ProbSeen部分,线上预测的时候不需要知道位置信息。实际上线后,此方案收益不明显:用户点击率提升 0.9%,用户人均点击篇数降低0.7%,内容曝光提升1.0%,内容点击率降低0.3%。
美团广告系统位置偏差的CTR模型优化方案
方案一(基于深度位置交叉网络DPIN):
DPIN模型由三个模块组成,分别是处理J个候选广告的基础模块(Base Module),处理K个候选位置的深度位置交叉模块(Deep Position-wise Interaction Module)以及组合J个广告和KK个位置的位置组合模块(Position-wise Combination Module),不同模块需预估的样本数量不一样,复杂模块预估的样本数量少,简单模块预估的样本数量多,由此来提高模型性能和保障服务性能。通过这三个模块的组合,DPIN模型有能力在服务性能的限制下预估每个广告在每个位置上的CTR,并学习位置信息和其他信息的深度非线性交叉表示。 DPIN结构
DPIN结构
在深度位置交叉模块中,提取用户在每个位置的行为序列,将其用于各位置上的用户兴趣聚合,这样可以消除整个用户行为序列上的位置偏差。接着,采用一层非线性全连接层来学习位置、上下文与用户兴趣非线性交叉表示。最后,为了聚合用户在不同位置上的序列信息来保证信息不被丢失,采用了Transformer来使得不同位置上的行为序列表示可以进行交互。
位置兴趣聚合
令Bk是k个位置用户历史行为序列,将一系列行为特征都embedding。 位置兴趣聚合公式
位置兴趣聚合公式
第k个位置行为序列的聚合表示bk可以通过注意力机制获取 注意力机制计算bk权重
注意力机制计算bk权重
其引入当前上下文c去计算注意力权重,对于与上下文越相关的行为可以给予越多的权重。
Transformer Block Transformer模块计算
Transformer模块计算
位置组合模块
位置组合模块的目的是去组合J个广告和K个位置来预估每个广告在每个位置上的CTR,采用一层非线性全连接层来学习广告、位置、上下文和用户的非线性表示,第j个广告在第k个位置上的CTR可以由如下公式得出: CTR公式
CTR公式
其中包括了一层非线性连接层和一层输出层,是E(k)位置k的embedding表示,σ(⋅)是sigmoid函数。
整个模型可以使用真实位置通过批量梯度下降法进行训练学习,采用交叉熵作为的损失函数。 实验对比
实验对比 模型推理时间
模型推理时间
三、总结
在搜广推场景中我们样本是基本不可能作为无偏的,常规做法也就是在模型侧进行纠偏让模型能学到位置偏置,从而真正能抓到用户喜欢质量高的内容,目前感觉比较有效且不会影响线上推理服务的方法,我认为是对模型进行多任务建模,一个任务学习CTR一个任务学习位置,让模型有隐式纠偏能力,线上直接预测CTR结果会比之前更为精准。在nlp中也有类似的方法,就是在做ner任务时想同时结合span方法和CRF方法的优点,在训练时使用多任务学习,在最后推理时拆掉CRF,让模型学习到CRF序列观测的能力,多任务和多目标在实际业务中也是应用广泛。
四、参考文献
1、位置偏差在马蜂窝推荐排序中的实践_马蜂窝技术的博客-CSDN博客
2、SIGIR 2021 | 广告系统位置偏差的CTR模型优化方案
4、定西:[论文分享]华为PAL论文:解决推荐、广告中的position-bias问题


{kind=link}