

AIGC与大模型赋能机器人智能控制
导读 本文将探讨强大的 AIGC 生成模型和 ChatGPT 大模型,如何为智能机器人服务。
主要内容包括:
-
AIGC 简介
-
AdaptDiffuser
-
Embodied AI
-
Embodied GPT
分享嘉宾|穆尧 香港大学 在读博士生
编辑整理|宋世伟
内容校对|李瑶
出品社区|DataFun
01AIGC 简介
1. AI 落地的理想与现实
首先为大家简要介绍一下 AIGC,在图像领域 diffusion model 是目前最强大的 AIGC 模型,它在图像上具备非常强的生成能力,特别是能够针对 text prompt 给出非常好的生成效果。

我们通过回顾从最简单的生成式模型 VAE 到 Gan,再到 normalizing flow、diffusion model 的发展历程,来看一下 diffusion model 为什么强大。先看一下 VAE,这个是大家学生成式模型最开始去学的,一般来讲有一个encoder和一个decoder,encoder 会把这个 x encode 到 z 隐变量上,再有一个 decoder 去把这个隐变量 z decode 回原来的这个 x 空间上。

VAE 也可以做成多层级联的模式,也就是说它可以设置若干个中间的变量,这样一个多层级联的模式可以让它逐步地去学会把一个分布映射到一个更复杂的分布上,但是我们会发现,比如从 Z2 到 Z1,再从 Z1 到 x,每一个过程都需要一个 encoder 和 decoder,层级数越多,它所需要的 encoder 和 decoder 就会越多。

下一代的生成式范式就是 Gan 和normalizing flow。每一个生成式模型都可以在机器人上或者在 RL 上找到一个典型的应用,比如 GAN对应到 RL 或者 imitation learning 上的例子,就是 Gail 这样一个生成对抗式的 imitation learning,它的特点是需要学习一个判别器,所以 GAN 这种方式最典型的特点就是它的收敛性不是很好,它会比较不稳定。
Normalizing flow 则非常稳定,它的整个更新是这个梯度有一个解析解,所以它并不需要学习一个 discriminator,同时它也有要求,就是它里面每一个变换层的函数都要是一个可逆的函数,这样才有一个好的性质。
由于它对每一个变换层的可逆性的要求,它就不能够采取非常复杂的网络,比如说用 Transformer 或者用 unet 等一些在生成式模型上效果比较好的模型,它要求每一个变换的函数是可逆的,所以它就很难去 scale up,很难去与最先进的网络结构相结合。

那么我们能不能有一个非常强大的生成模型,不需要去学一个 discriminator,也没有对中间的这些变换函数有这么强的相应性要求,答案就是 diffusion model,它包括一个前向的扩散过程和一个反向的去噪过程,也就是说它会将一张图片逐渐加噪,每一步只加一点点小的噪声,逐渐把这张图片加到一个纯高斯噪声的状态。前向加噪过程中每一步加的噪声的方差是人为设计的,所以从原图空间到 noise 的高斯分布空间,全程不需要学 encoder,也就是说这里面没有任何网络 encode 的环节,与多层级联 VAE 最大的区别就是,它只需要去学一个逆向的去噪过程,在每一步学会把当前图像剪掉一部分噪声。然后经过比如 1000 步的还原之后,它可以还原出非常高清的图像。它只需要去学逐渐去噪的网络,而不需要去学前面的 encode 网络,所以它会比多层级联的 VAE 要强大很多,同时它的训练也是稳定的,它对于变换函数没有任何的相应性要求,所以只要是学界有新的 powerful 的结构出来就可以去用。

图中就是前向 diffusion process 的一个表达,我们可以看到逐渐地会在里面加一个人为设计方差高斯分布,而且按照这样的一个 design 好的高斯分布噪声去加,那么最终可以理论上保证,在迭代足够多步数T,可以趋近于一个 0-1 高斯分布。

去噪过程就是我们刚刚说的,它去逐渐地去学会一个以 Theta 为参数的网络,从当前的图像和当前的时间步,根据当前的图像和当前的时间步去学会需要 remove 掉哪一部分噪声。
02Adaptdiffuser
上面介绍了 diffusion model 在图像上是如何做的。那我们想一想强化学习上怎么做,首先要转换一个视角来看强化学习的问题。

我们以 model based RL 举例,它有两个关键的步骤,一个是需要去学一个预测的模型,也就是说给了当前的状态和当前的动作,那么转移到下一个状态会是什么?这个实际上是 system dynamics,那么有了 system dynamics 之后,再去优化每一步的 policy,也就是说需要去优化每一步的 action,使得每一步最终由 s 和 a 所构成的 reward 的累加和达到最大。
用一个全新的视角来看,它实际上是一个 (S,A) 序列的优化问题,这个 (S,A)序列实际上是一个 trajectory,所以我们可以把它转换成一个轨迹的生成问题,也就是说生成一系列的(S,A)这样的序列。
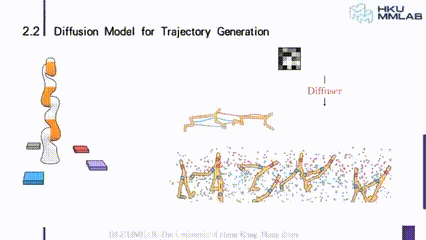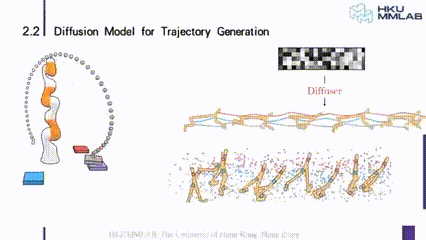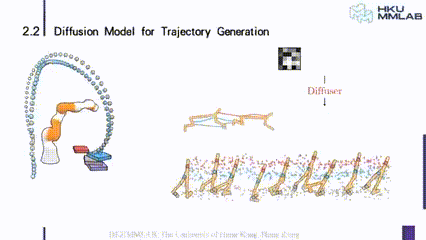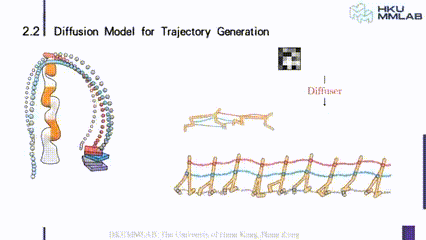
有了这样的一个观点之后,我们就可以把比如机械臂的控制,或者是一个小人跑步往前走的这样一个运动建模成一个轨迹生成的运动。我们可以像图示这样,从噪声出发去逐渐的 denoise,最终形成一个符合我们要求的轨迹。

上图就是用 diffusion model,也就是说用 AIGC 的范式把机器人的控制问题转换成一个 trajectory 的生成问题。
具体的做法还是比较简单的,首先我们在每个时刻,把它当前的状态 s 和 a concat 起来,在纵向的维度上是 s 的维度加上 a 的维度,在横向上实际上是时序的维度,图中的例子假设了是六步,所以就是六维,如果是 T 步的话就是 T 维,所以我们就可以把它转换成为 m+n 维的 Tensor,然后去做 diffuse,这可以用一个简单的一维卷积来实现。
在图像中,比如 unet 是一个逐层级联的结构,它的基本模块是图像上的卷积,对于 trajectory 是比较简单的,我们也采用了 unet 这样一个之间有连接的结构。但是用一维的卷积就可以满足要求,最终可以把一段纯噪声初始化的 trajectory,逐步地去 denoise 成为一个能够对机器人精准控制的 trajectory,同时 denoise 的步数越多, trajectory 就会越精准、越平滑。

另外一个问题就是,仅靠 diffusion 直接去做轨迹生成,是不是能够满足我们机器人的要求?我们发现它生成的能力非常大程度上受限于训练集,也就是说它所见过的数据。然而机器人领域的专家数据是远远要小于 AIGC 领域的。
其实从理论上我们可以去推导,也就是最终生成 trajectory 的 behavior 的概率分布,可以近似成以 Theta 为参数的 diffusion model 所生成的概率分布,再乘以一个 guidance function,这个 guidance function 实际上就是在 sample 过程当中每一步去加一个梯度的指引,让 denoise 过程中对每一小步 noise 去做一个指导性的指引。
参见图中的例子,假设它见过的数据是图中三张小图的第一张,但实际上期望的这个 trajectory 是第三张的样子,也就是说会有两个障碍物,需要绕过去,那么怎么去做呢?我们给这样一个 guidance function 的热力图,通过 reward function 可以很快很方便给出,也就是说它生成了结果,再结合这个 guidance function,我们就可以生成满足我们要求的一个 trajectory。
那么具体从数学上怎么去做呢?实际上非常简单,我们在生成这一条 trajectory 的时候,刚才讲过它是一个 Tensor,直接去用 diffusion model 去生成。在每一个时间步,根据 s 和 a 都可以算出来一个 reward,我们可以把里面的每一个 reward 都求出来,然后我们又有一个可导的 reward function,就是 s 和 a 的函数,所以我们最终算出来的 h(τ),也就是 guidance function,它可以对 s 和 a 都求出其偏导数。这实际上就是对 s 和 a 在生成过程中的梯度指引,有了这个梯度的指引,我们就可以在它 denoise 的过程当中逐步引导它生成我们想要的样子。

另外一种指引的方式就是 goal-condition 的指引,比如我们想让机器人把插销插到插座里,那么最终有没有插成这样的一个 goal state,距离这个插成有多远,它实际上对 s 和 a 也都是可导的,所以通过这样的 guidance 我们就可以让它去完成这样的一个任务。

接下来如果要把这样的一个 diffusion 的 planning 做到足够强大,它的一个核心的局限其实还是训练集,我们只靠加一些 guidance 可以让它比原来生成得更好,但是我们要想让它 optimal 是比较难的,那么怎么办呢?一个非常清晰的思路就是如果这个 diffuser 可以完成自进化,就是说可以在新的环境里面根据新的任务,去自进化地生成更多的数据。因为这本身是一个生成模型,所以可以生成更多的在这个场景下的虚拟数据,用这些虚拟数据去把自身生成的能力提高,再配合刚才讲的 guidance,这样不断地轮回,不断地自进化地适应这样的一个环境,最终就可以在新的环境、新的任务当中得到非常好的一个效果。举个例子,按照图中可能见过的是右边的迷宫,但是 testing 的时候是左边这样的迷宫。

这是我们在 ICML2023 的一篇 Oral 的文章,叫 AdaptDiffuser,我们希望做一个具有强自适应能力、强自进化能力的 Diffusion model for robotic planning。具体流程为,首先,根据仅有的一部分离线专家数据,先初始化一个 diffusion model,相当于是一个 pre train;接下来一个很重要的环节,就是专家数据里面可能只有若干个有限的目标,有限的任务,我们首先要做一步任务的生成,比如迷宫里面的起点、终点的设置,不同迷宫的类型,比如机械臂要操纵的物体的类型,操纵物体要完成的具体任务,比如是把物块叠起来,还是把物块放到碗里,还是要去开抽屉等等。
生成多种多样的 goal point 之后,再利用我们刚才介绍的 reward guidance 和 goal guidance 的技术去 guide 初始化的 diffusion model,在这些任务上生成跟这些任务有关的虚拟数据。生成出来的数据并不一定都是可用的,我们会选择一部分有用的,也就是 reward 相对较高的,并且其 system Dynamics 相对比较真实的。满足这些评价指标的数据,我们会最终作为一个 diverse synthetic data 去帮助我们的 model 学习,通过这样一个自进化的链路,使它逐渐地去见更丰富的任务,更丰富的样本,从而使得自己在机器人任务上变成一个越来越强大的模型。

接下来右边是有两个例子,一个比如迷宫里面,起点和终点可以随便指定,它可以去生成一个trajectory。它可能一开始生成得不太好,但是我们经过 reward 的 guide 和筛选,可以把它的结果生成的越来越好;另外一个是 manipulation 任务里面不同的 goal,比如说每个物块可能有自己独立的 goal state,我们希望把它放在不同的位置上,比如我们希望把绿色物块放到黄的物块上面,或者把这 4 个物块按照例如红黄蓝绿的顺序去排,可以是千变万化的。
我们可以看一下详细的 framework,它实际上在生成了 diverse task 后,每一个task,每一个 goal 都有对应的 reward function,我们利用 reward function 所计算出来对状态 s 和 a 的 guidance 去 guide denoise 的过程,从而生成更多的数据加入到 data pool 中,帮助我们去 update 我们的 diffusion model。如此循环往复,就可以训练出来一个更强大的生成模型。

刚才讲了 diverse task generation,实际上我们也可以利用如 ChatGPT 这样先进的工具去帮助我们。第一比如说生成更多的地图,生成地图有一些具体的要求,比如任意指一个起点和终点,需要至少存在一条可达的路径才可以。所以它有若干合法化的要求,我们发现通过合理地设计 prompt,把这些设计的规则和合法性的要求给 ChatGPT 说清楚,它就可以帮助我们生成出来一些跟当前的环境非常不一样的地图,从而帮助我们进行更好的 diffusion model 的训练。

看一下实验效果,关于自进化方面,我们可以实现两个完全不相干任务知识的迁移,比如左边这样的机械臂它是把所有小物块都叠在一起,它训练的过程当中只见过这样一个任务的数据,但我们右边这个任务,需要把每一个物块放到一个规定的 position,而且顺序还有指定颜色的要求。这个实际上和左边这个 Stackin 的任务是完全不一样的任务,但是我们可以实现很好的迁移,有一个很好的效果。

同时在迷宫地图上也会有一些这样的例子,比如说在一些 hard case 上,我们的模型都要比普通的 diffusion model 去做 planning 效果要好。同时比如临时加一个新的任务,在一个新的地图里面,不仅要求从起点能到终点,还要求在导航过去的过程当中,顺带去捡一个金币,捡到这个金币就给更大的奖励。那么怎么去捡这个金币?那实际上需要去把 reward 这个 guide adapt 过去,我们发现我们的 adapt diffuser 在不管是原任务还是捡金币的任务都可以表现比较好。
03Embodied AI
接下来的一个 topic 就是大模型和机器人智能控制。ChatGPT 具有非常强的推理能力,同时现在 Meta 所推出的 segment anything,又提供了非常强大的视觉上的大模型,所以在视觉大模型和语言大模型蓬勃发展的这一时期,要实现一个能够为人类具身地去服务的AGI,具身智能可能会成为这样的 AGI 的最后一公里。比如我们希望有一个机器人,我说一句话,我现在渴了,首先它能分析出来,你可能需要一杯水,我需要给你递水,这个其实 ChatGPT 已经都打通了。那么它怎么去把这个水递过来?那可能需要一个实际的机器人去导航到饮水机前面按这个按钮,把水接出来,再把水端到你的面前。所以这一套控制实际上可能会是 AGI 的最后一公里,如果实现的话,实际上我们可以至少在室内场景实现一个基本的 AGI 了。

它的挑战也是不小的。首先,需要有一个非常好的具身的认知系统,也就是第一人称视角的,区别于我们现在很多互联网上数据都是第三人称视角。和传统 CV 不同的地方是,它不能只知道这是一个橱柜,还需要知道这个橱柜怎么打开,需要知道橱柜上有一个把手,自己需要去拨动这个把手,才有可能把这个门打开。
第二,它需要有一个非常高质量的可执行的规划能力,而实际上这个规划能力和它的第一部分认知能力是相耦合的,我只有认知到了我需要去打开这个橱柜,我得去关注它这个 handle,才能规划出来第一步需要去靠近这个 handle,第二步需要去抓这个 handle 或者拨动这个 handle 来去开门。
第三个问题就是需要有一个强大的 goal-condition physical interaction,也就是说需要有一个 policy 去执行,知道去抓这个handle,具体怎么去抓。

这就是具身智能的三大挑战。

针对上述挑战,我们首先构建了一个非常强大的数据集,叫做 EgoCOT,都是第一人称视角的视频,然后基于这些视频,我们去做了多模态具身思维链的扩充。比如当前的 task 是 open a drawer,那么 open drawer 需要干什么,它需要有一个 plan,就是 grasp the handle with the gripper and pull the handle,然后我们还会把这样的一个 plan 再整理成具体的动名词搭配的形式。普通 caption 只会到第一步,就是 open a drawer,但是我们会有非常细致的底层规划的标注,在这样的标注下,我们可以去让它去学到更好的高质量规划能力。

第二,我们利用这样的一个多模态的具身思维链进行了 vision 和 language 的 Pre train,我们采用了 large vision model 和 LLaMA。中间设计了一个 embodied-former,会根据视觉的输入以及一些可学的 embodied queries 和 test queries,去 query 出当前跟这个任务最相关的信息。同时通过 Mapping 到 language 的模态之后,它可以去完成 embody planning,比如说需要去执行一个任务,那么可以给出这个任务的规划,并且可以总结成 structure 的形式。第二点就是它可以去做 video 的 caption、 video 的 QA 还有 multi-round,也就是多轮对话,多轮对话的核心意义是它可以亲自去执行,执行的时候它可能会失败,但它可以观察自己失败的视频进行 revise。比如它第一轮给出的 planning 可能是第一步有一个偏差,那么它可以去观察自己执行这个 planning 的时候遇到了哪些问题,可以去修改自己的 planning,这其实是设计多轮对话功能的一个比较重要的意义。

同时在底层的实现过程当中,我们会在 language 层面把给出每一步的 planning 和 embody query 做 attention,基于它的 self attention 可以 query 出当前的观测下具体执行到哪一步,需要去关注的是哪个部分。比如要 grasp 这个handle,那么需要的是从 vision 去获得 handle 的信息,最终 map 到 action 上,这就是 embodied GPT 整体的流程,我们通过这样一个 embodied former 的自注意力机制,去自动地连接了 high level 的 planning 和 low level 的 control,形成了一个闭环。
,时长01:16
接下来展示一个简单的 demo,大家可以看一下。你可以去问怎么把右边橱柜打开,它会有若干个 step,然后根据这若干个 step 的 planning 逐步地执行。
另外是在 Meta word 上的例子,比如说用锤子去钉钉子的任务,它可以去生成若干个 step,也是逐步地去执行,而且它生成的可执行度还是比较高的。
这两个就是在机器人上特定 DOMAIN 的例子。我们还设计了一个在 general 的 VQA 的任务,这个图片就是我工位附近的饮水机,它可以去对这个图片生成一个比较 dense 的 caption。然后我说我需要去做一杯咖啡,需要怎么去做。它可以生成从 1 到 10 步这样一个很详细的规划。
以上是本次分享的内容,谢谢大家。
04Q&A环节
Q:GPT 回复动作的颗粒度是怎么定义的?有多细致?
A:这是一个非常好的问题,这也是我们为什么要去做这个数据集的一个原因。首先我们这个是训了一个多模态的大模型,不是把 ChatGPT 嵌进来,而是一个从视觉到语言的一个多模态模型。然后第二点就是颗粒度,我们其实可以去问同样的问题,ChatGPT 给的回答是非常粗颗粒度的,这实际上在具身智能领域是很难去非常强的可用性和实用性的,所以我们才做了 EgoCOT 的这个数据集,它的颗粒度可以具体到 part level。比如说对于一个茶杯它可以关注到这个茶杯的把手;比如说对橱柜,它也可以关注到橱柜的把手;然后包括比如说灶台上的旋钮,比如煤气开得大一些或小一些,或者档位的按钮等等。
因此我们所提出的 EgoCOT 以及我们所建立的 embodied GPT,它的颗粒度是要比 ChatGPT 要好的,因为我们在这个 DOMAIN 上进行了比较好的训练,特别是我们也专门造了一个数据集,为了让它具备这样细颗粒度的输出规划的能力。
Q:diffusion model 决策的时候 decode 速度慢吗?
A:diffusion model 的 planning 的速度其实一直是大家非常关心关注的问题。但是其实在图像生成的领域,比如最原始的 DDPM,它的生成是比较慢的,但是我们现在基于 score function 的微分方程离散化的一系列加速采样的思路,它可以把 diffusion planning 最终的 inference 的时间效率提升到机械臂可接受的一个程度,但其实它的加速仍旧是学界一直在做的事情。
Q:下个问题是说 diffusion 模型生成虚拟的图片来让机器人学习吗?
A:我们生成的不是虚拟图片,而是虚拟的轨迹,是一条连续的轨迹。比如之前图示所说的,有若干个带颜色的点所构成的这样一条轨迹。然后它是当包括当前机器人的state,当前的状态以及它的 action。我们生成的是对每一个任务这样的一个轨迹。如果它是 image level 的 observation,它会包含这个 image,但是它同时还包含了机器人自己的 action 是非常关键的。
以上就是本次分享的内容,谢谢大家。


{kind=link}